BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
프리트레이닝과 전이학습
모델을 프리트레이닝하는 것이, 혹은 프리트레이닝된 모델이 모듈로 쓰는 것이 성능에 큰 영향을 미칠 수 있다는 건 너무나 잘 알려진 사실이다. 그렇다면 어떻게 프리트레이닝을 할 것인가? 많은 데이터를 비싸게 만들어야 하는 레이블 없이 사용할 수 있으면 좋을 것이고, 또 프리트레이닝 결과 학습된 모델이 특정 작업 뿐만 아니라 다양한 작업에 일반적으로 사용될 수 있는 범용성을 갖추면 이상적일 것이다. 이렇게 다른 과제를 수행하도록 학습된 모델을 가져와 또 다른 과제에 사용하는 방법을 전이 학습(Transfer Learning)이라고 부른다.
컴퓨터 비전에서는 프리트레이닝된 모델들이 널리 쓰이고 있었다. 바로 ILSVRC 2012 이미지 분류 과제에 대해 학습된 모델들이다.

추가적인 레이블이 있는 형태이긴 하지만 분류 레이블을 만드는 게 segmentation mask를 만든다거나 bounding box를 만들고 레이블을 단다거나 하는 것보다는 낫다. 거기다 이미 레이블이 달린 데이터가 있으니까 큰 문제는 아니다. 그리고 이런 이미지 분류 과제에 학습된 모델들은 다른 과제의 성능을 향상시키는데 사용할 수 있다. 심지어 더 놀라운 것은 이미지 분류를 더 잘 하는 모델이 다른 과제, 예컨대 segmentation mask를 만든다거나 bounding box를 찾는다거나 하는 과제에 대한 성능도 더 낫다는 것이다. 그래서 (지금도 그렇긴 하지만) 이미지 분류 과제를 더 잘 하는 구조를 만드려는 시도들이 있었다.
 ResNet
ResNet그렇다면 자연어 처리 과제에서는 어떨까? 자연어 처리에서도 프리트레이닝된 모델들은 많이 쓰였다. word2vec, GloVe, fasttext 같은 단어 임베딩 모델들이 프리트레이닝된 모델들로 흔히 쓰였다.

단어 임베딩은 보통 특별한 레이블 없이 단어들만 가득한 코퍼스에서 비지도적으로 학습될 수 있다. 그리고 단어들의 의미나 문법적 특성 등을 반영하도록 학습된 단어 임베딩 벡터를 자연어 처리 모델의 입력으로 사용하면 이미지 분류 모델을 다른 과제에 적용했을 때처럼 적지 않은 성능 향상이 나타나기도 했다.
그런데 이걸로 충분한 걸까?
당장 동음이의어와 다의어 문제가 걸린다. 아침이라는 단어는 어떤 시점을 가리키는 것일 수도 있고 먹는 것일 수도 있다. 날이 밝은 시점이라는 의미로 쓰였다고 해도 화자의 의도에 따라 그 의미가 미묘하게 다를 수도 있다. (월요일 아침과 토요일 아침의 미묘한 차이 등.) 그러나 단어 임베딩은 각각의 단어만 보기에 이런 차이와 미묘함을 반영하기에는 한계가 있다.
그렇다면 어떻게 해야할까? 아니 애초에 인간은 단어의 수많은 가능한 의미 중에서 어떻게 의미를 혼동하지 않는 것이 가능한가? 바로 맥락의 힘일 것이다.
- 월요일 아침이 밝았다.
- 간단한 아침을 먹었다.
새삼스러운 예제이지만 어쨌든 인간은 아침이라는 단어 이후에 이어지는 단어들을 통해 아침이라는 단어의 의미를 포착해낸다. 날이 밝은 시점을 먹었다고 생각할 이유도 식사가 밝아졌다고 생각할 이유도 없기 때문이다.
그렇다면 어떻게 맥락적 정보를 반영한 단어 임베딩 벡터를 만들 수 있을까? 단어 임베딩 모델들을 생각해보자. 많은 단어 임베딩 모델들의 아이디어는 이 단어와 어떤 단어들이 같이 등장하는지를 통해, 다르게 바꿔보면 이 단어를 통해 같이 등장하는 단어를 예측하는 방법으로 학습하자는 것이었다. 예컨대 아침이라는 단어는 밝았다는 단어와 혹은 먹었다는 단어와 같이 등장하니 이 아침이라는 단어를 통해 이 두 단어를 예측하도록 하면 대충 아침은 밝기도 하는 것이고 먹기도 하는 것이라는 것을 학습할 수 있다는 것이다. 그렇다면 단어 하나 뿐만 아니라 맥락을 구성하는 이전의 단어들도 결합하도록 하면 되는 것이 아닌가?
이런 식으로 나아가면 결국 언어 모델으로 이어지게 된다.
언어 모델은 텍스트의 확률을 추정하는 모델이다. 즉 월요일 아침이 밝았다라는 문장의 확률을 추정하는 것이다. 아니 그 확률을 어떻게 알아? 그렇게 생각하는 분들도 월요일 아침이 밝았다는 문장이 월요일 아침이 사라졌다라는 문장보다는 (개인적인 바람과는 별개로) 더 있을법하다고 생각할 것이다. 그러니까 확률이 더 높다고 할 수 있지 않을까? (물론 텍스트에 확률을 부여한다는 아이디어에 반대하는 언어학자들도 있다. 대표적으로 촘스키가 그렇다고 한다.)
그렇다면 어떻게 텍스트의 확률을 추정할 수 있을까? 이 문제에는 확률의 연쇄 법칙(chain rule)을 사용할 수 있다. 텍스트의 각 단어에 해당되는 $x$, $y$, $z$라는 변수가 있다고 하자. 그렇다면 x = a, y = b, z = c라는 시퀀스, 즉 단어의 시퀀스인 텍스트의 확률은 어떻게 될까? 이는 $x = a$일 확률, $x = a$일때 $y = b$일 확률, $x = a, y = b$일 때 $z = c$일 확률의 곱이 된다. 즉 이전 변수들에 대해서 다음 변수의 확률을 구하고, 그리고 그 변수들을 통해 다시 다음 변수의 확률을 구하는 식으로 전체 시퀀스의 확률을 계산할 수 있다.
그렇다면,
- $x$로 $y$의 확률을 예측하도록 학습
- $x$, $y$로 $z$의 확률을 예측하도록 학습
- ...
위와 같은 과정을 통해 시퀀스의 확률을 계산하는 모델을 학습할 수 있다는 것이다. 그리고 이런 문제는 RNN을 아주 자연스럽게 적용할 수 있다. RNN이 대충 $z = f(y, f(x))$와 같은 형태의 함수라고 생각해보면,
- $x$로 $y$ 예측 -> $y = f(x, 0)$
- $x$, $y$로 $z$ 예측 -> $z = f(y, f(x, 0))$ 3, ...
위와 같은 형태로 매칭되기 때문이다. RNN 튜토리얼에 흔히 나오는 텍스트 생성을 위한 언어 모델 학습 과정이 꼭 이렇게 생겼다.
그런데 대체 이게 단어의 의미 파악에 어떻게 도움이 되는 것일까?
뒤의 단어를 통해 앞의 단어를 예측하는 언어 모델을 생각해보자. (언어 모델은 꼭 앞에서 뒤로 나아갈 필요는 없다.) 아침이 밝았다라는 단어들 앞에 올 수 있는 단어가 어떤 것이 있을까? 아침이라는 단어 뿐만 아니라 밝았다라는 단어까지 고려하므로, 또는 고려할 수 있기 때문에 날이 밝은 시점이라는 의미의 아침이라는 단어 앞에 올 수 있는 단어가 등장할 확률이 높을 것이다. 여기서는 월요일이라는 단어가 왔다. 반대로, 아침을 먹었다는 단어들 앞에는 식사라는 의미의 아침이라는 단어 앞에 올 수 있는 단어가 등장할 확률이 높을 것이다. 여기서는 간단한이라는 단어가 등장했다.
즉 언어 모델을 통해 같은 단어가 다른 정보를 출력하게 된 것이다.
사실 언어 모델이 자연어 처리를 위한 프리트레이닝으로 유용하다는 것은 상당히 이전부터 알려져 있었다. 바로 생각나는 건 Semi-supervised Sequence Learning (2015) 같은 논문이다. 1 (사실 딥 러닝 판이 아니고서야 3년 전 논문을 상당히 이전부터 알려져 있었다는 증거로 사용하는 건 부적절하긴 하지만.)
그렇지만 언어 모델을 사용한 프리트레이닝이 지금처럼 화제가 된 것은 올해 초 나온 논문인 ULMFiT 2 이후라고 봐도 좋을 것 같다. 요약하자면 언어 모델을 열심히 트레이닝 시킨 다음 논문에서 제안하는 여러 트릭을 사용해 각종 텍스트 분류 과제에 대해 파인 튜닝을 하면 여러 벤치마크를 깨뜨릴 수 있다는 것이다.
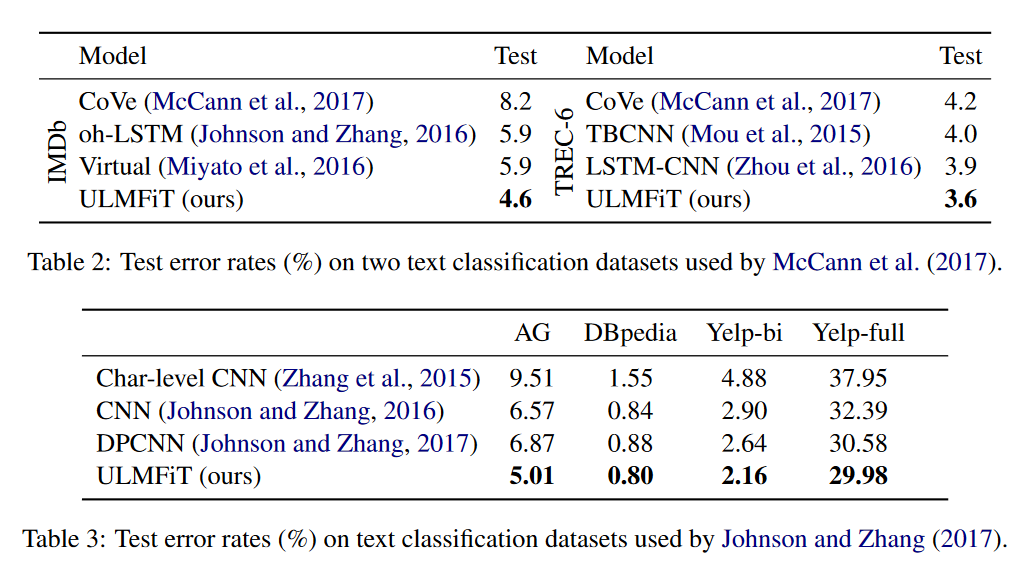
ULMFiT는 영화 평점 분류 같은 좀 전통적인 과제에 적용된 모델이었다. 그러다가 SQuAD QA 같은 과제에 프리트레이닝된 언어 모델을 사용하는 시도가 등장하게 된다.

그것이 바로 ELMo이다. ELMo의 아이디어는 앞에서 뒤로 진행하는 언어 모델과 뒤에서 앞으로 진행하는 언어 모델을 결합하는 것이다. 위의 두 아침 문장 예제에서 월요일이라는 단어와 밝았다라는 단어 둘 다 아침이라는 단어에 대한 정보를 갖고 있다. 그러니 양방향의 정보를 가져오는 것이 자연스럽다. 또한 언어 모델을 학습하기 위해서 다층의 RNN을 사용하게 되는데, 최종 레이어의 출력 뿐만 아니라 이전 레이어의 출력도 또 유용한 정보를 갖고 있을 수 있으므로 가져와서 결합하자는 것이다.
그리고 그랬더니,

벤치마크를 또 깨부수기 시작했다. 이젠 프리트레이닝한 모형을 사용해 전이학습을 하지 않으면 안 되게 된 것이다. 마치 컴퓨터 비전에서 프리트레이닝한 분류 모형을 쓰는 것이 거의 당연하게 여겨지는 것과 비슷하게...
와, 대단하네요! 그러면 이제 가도 되죠?
그러나 이 이야기는 아직 끝나지 않는다. 누군가가 이 프리트레이닝 과정에서 LSTM 같은 RNN 모형을 쓰는 것에 불만을 갖기 시작한다...
RNN을 넘어
시퀀스 데이터에 대해 RNN은 아주 자연스러운 모델이다. RNN의 핵심인 시퀀스 내의 모든 스텝에 대해 동일한 네트워크를 적용하되 (weight sharing), 각 스텝에서 이전 스텝의 네트워크의 출력을 받아오는 것이다. 이전 스텝의 출력을 가져오니까 이전 스텝의 정보도 사용할 수 있다. 그리고 그 이전 스텝은 또 이전 이전 스텝의 정보를 가져오니 이전 스텝의 출력에는 이전 스텝의 정보 뿐만 아니라 이전 이전 스텝의 정보도 포함되어 있는 것이다. 그러니까 계속 반복하면 이전 모든 스텝의 정보를 사용할 수 있는 것이다.
완벽하다!
물론 그럴 수 있다는 것이고 실제로 그게 그렇게 잘 되는지는 별개의 문제렷다. 현재 스텝 ($t$)에서 이전 이전 스텝 ($t-2$)의 정보를 가져오려면 이전 스텝 ($t-1$)을 거쳐야 하니 $t-2$의 정보를 $t$에서 써먹자면 $t-2$의 정보가 $t-1$을 거쳐서 $t$까지 잘 전달되어야 한다. 1, 2 정도면 문제가 아니겠지만 한 $t-100$의 정보를 가져와야 한다면? 정보가 거치는 단계가 많아지니 정보를 가져와서 쓰기도 어렵고 또 그렇게 하도록 학습하기도 어려워진다.
거기다 네트워크를 한 스텝에 적용하고, 그 결과를 다음 스텝에 입력해서 다시 결과를 가져오는 식으로 순차적으로 처리해야 하니까 연산 자체도 순차적으로 할 수밖에 없다. 병렬로 한 방에 처리할수록 효율적인 GPU에는 그닥 적절한 구조는 아니라 하겠다.
그래서 누군가가 CNN을 써보는 건 어떨까 하는 생각을 하게 된다. CNN도 각 영역에 대해 동일한 네트워크를 적용하는 것은 비슷하니까 2d인 이미지가 아니라 1d인 시퀀스에 적용한다고 생각하면 그만인 것이다. 처음에는 텍스트 분류에 적용되었다가 4 데이터 특성상 길이가 매우 긴 (그러니까 초당 1만 스텝 이상) 시퀀스인 오디오 시그널에 적용되어 엄청난 성공을 거두게 된다. 5 그리고 기계 번역 과제에도 적용되어 6 7 한동안 SOTA도 찍고 좋은 시간을 보냈다.
그러면 역시 미래는 CNN이었나?

그러나 빠르게 변화하는 딥 러닝 판은 그러도록 내버려두지 않았다...
신경망 기계 번역과 주의(Attention)
뜬금없지만 시퀀스 A와 시퀀스 B가 있을 때 A를 B로 변환하려면 어떻게 해야할지 생각해보자. A와 B는 길이가 다르다. 그리고 A의 한 원소가 B의 어떤 원소와 대응되는지도 알 없다. 아니 그런 문제를 어떻게 풀어? 그런데 바로 그런 종류의 문제가 기계 번역에서 발생한다.
- (1) 아침을 (2) 먹었다 <-> [1] I [2] have [3] breakfast
(2)와 [2]를 대응시키고 [3]과 (1)을 대응시키면 될 것 같긴 한데 갑자기 튀어나온 [1]도 있다. 그런 규칙들을 다 지정할 수 있으면 할 수도 있겠지만 그게 가능했으면 번역 시스템 같은 걸 진즉에 만들 수 있었을 것이다.
대체 어떻게 해야 하나? 그런데 이 문제에 신경망을 적용하면서 인코더-디코더 구조가 등장하게 된다. 8 9
인코더-디코더 구조의 핵심은 다음과 같다.
- 시퀀스 A -> 인코더 -> 코드 -> 디코더 -> 시퀀스 B
그러니까 인코더가 시퀀스 A를 받아와서 그 의미 같은 정보를 코드로 잘 압축한 다음, 그 압축한 코드를 받아와 디코더가 시퀀스 B를 출력하는 것이다. 그러니까 길이가 달라도 상관 없고 시퀀스의 원소들을 서로 매칭하기 어려워도 상관 없다. 인코더가 알아서 정보를 전달할 것이고 디코더는 정보를 받아 알아서 잘 시퀀스를 출력할 것이기 때문이다.
이 구조가 잘 동작했고, 이게 된다! 라는 결과를 얻었지만 한 가지 문제가 있었다. 위에서 시퀀스를 인코더가 코드, 즉 하나의 벡터로 압축한다고 한 대목에 주목하시라. 짧은 문장이 들어온다면 문제가 없겠지만 문장이 길어진다면? 긴 문장을 하나의 벡터로 압축하기는 어렵지 않을까? 실제로 그랬다.
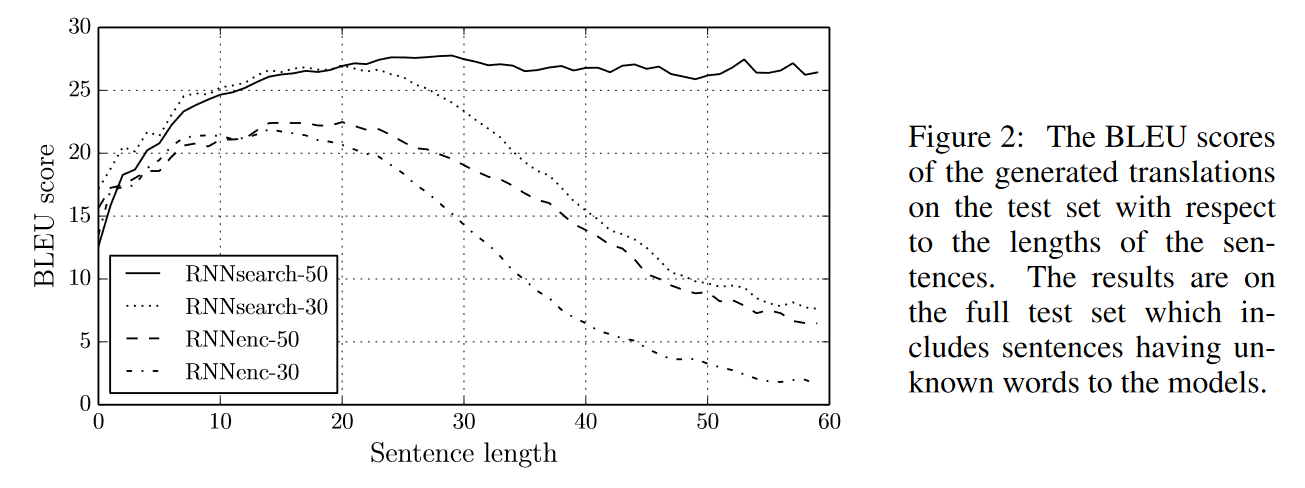
그리고 이 유명한 대사가 등장하게 된다.
You can’t cram the meaning of a whole %&!ing sentence into a single &!*ing vector! - Ray Mooney
그러면 어떻게 해야 할까? 길이가 길어지면 길어지는 만큼 코드의 길이도 길어지게 하면 된다. 그런데 그러면 문제는 원점으로 돌아가서 시퀀스의 길이가 달라지는 문제가 다시 등장한다.
그런데 관점을 바꿔서, 인코더가 시퀀스의 길이를 줄이려고 하지 말고 디코더가 알아서 시퀀스에서 필요한 것을 뽑아가도록 하면 되지 않을까? 그런 아이디어에서 등장한 것이 주의(Attention)이다.
주의 메커니즘을 간략하게 설명하면 이렇다. 시퀀스 $A = (a_1, a_2, a_3)$, 시퀀스 $B = (b_1, b_2, b_3)$가 있다고 하자. 과제는 시퀀스 A를 시퀀스 B로 바꾸는 것이다. 이 때 디코더는 시퀀스 B의 원소 $b_1$, $b_2$, $b_3$를 생성하게 되는데, 이 원소들 $(b_1, b_2, b_3)$을 생성하기 위한 정보들을 인코더가 인코딩한 시퀀스 $A = (a_1, a_2, a_3)$에서 가져올 수 있다고 생각해보자. 우선 $b_1$을 생성하려면 $(a_1, a_2, a_3)$에서 어떤 원소를 가져와야 할까? 여기서 원소를 직접 가져오는 대신 가중치 $(w_1, w_2, w_3)$를 주는 문제로 바꿔보자. 그렇다면 원하는 정보 $c$를 $c = w_1a_1 + w_2a_2 + w_3a_3$와 같이 구할 수 있을 것이다. 중요한 원소에 해당하는 가중치가 1이 되고 중요하지 않은 원소에 해당하는 가중치가 0이 된다고 하면, 결과적으로 중요한 원소를 가져오는 결과가 되는 것이다.
이제 $w_1$을 구하기만 하면 된다. 이건 적절한 함수 $f$를 설정해서 구하면 된다. $w_1 = f(a_1, b_1)$. 복잡하게 생각할 필요는 없다. 시퀀스의 원소를 벡터로 보면 두 벡터의 내적 $w_1 = \mathbf{a}_1\cdot\mathbf{b}_1$ 을 구하는 정도로도 충분하다.
자, 이제 다 끝났다! 이제 $f$를 모델 학습 과정에서 학습되도록 하기만 하면 된다. 그러면 결과적으로 디코더가 알아서 인코더에서 필요한 정보를 가져오는 모델이 만들어지는 것이다.
정말로 이게 전부다. (기술적인 디테일을 제외하면.) 마법 같은 일이지만 이런 구조만 만들어주면 나머지는 알아서 학습된다.
주의 메커니즘은 기계 번역 뿐만 아니라 수많은 과제에서 효과적이라는 것이 밝혀졌다. 심지어 시퀀스 하나를 처리하는 경우에도 유용했다. 위에서 RNN은 이전 스텝의 정보를 사용하기 위해선 여러 스텝을 거치더라도 이전 스텝의 정보를 계속 보존할 수 있도록 학습되어야 하는 문제가 있다는 것을 보았다. 위에서 한 문장에 대한 정보를 어떻게 벡터 하나에 집어넣을 수 있겠느냐고 했는데, 마찬가지의 문제가 RNN에서도 발생한다. 즉 $h_{t-1}$로 $h_t$를 예측하게 되는데, 그러므로 $h_{t-1}$은 $h_t$, 그리고 $h_t$ 뿐만 아니라 $h_{t+1}$를 예측하기 위한 이전의 모든 정보들, 즉 $h_{t-2}, h_{t-3}, \dots$에 대한 정보를 갖고 있어야 하는 것이다.
그런데 만약 현재 스텝에서 필요한 정보를 이전 스텝에 직접 접근해서 가져올 수 있다면? 굳이 이전 스텝의 정보를 계속 보존할 필요가 없다. 그러니까 이전 스텝의 정보를 직접 가져올 수 있도록 주의 메커니즘을 달아주면 된다. 자기 자신에 대해 주의 메커니즘을 사용한다고 해서 이를 자기 주의(Self Attention)이라고 부른다. 12 13 요령은 비슷하다. 다른 시퀀스 B를 사용하는 대신 시퀀스 A를 사용해서 시퀀스 A의 정보를 가져오도록 만드는 것이다.
여기까지 오니 이상한 - 그렇지만 획기적인 - 발상을 떠올린 사람이 등장했다. RNN을 시퀀스 데이터에 사용했던 이유가 무엇인가? 이전 스텝의 정보를 사용해서 각 스텝들 사이의 관계를 반영하여 시퀀스를 처리하기 위함이었다. 그런데 자기 주의 메커니즘을 사용하면 마찬가지로 시퀀스 내에서 이전 스텝의 정보를 가져와 결합할 수 있다. 그렇다면 굳이 RNN을 쓸 필요가 있을까?
트랜스포머
2017년 중반 Attention Is All You Need라는, 대충 어텐션을 쓰면 다 됨 ㅋ 정도의 뉘앙스를 가진 제목의 논문이 아카이브에 등장했다. 14 이 논문의 요점이 바로 이런 것이었다. RNN을 쓸 필요는 없고 주의 메커니즘만으로도 시퀀스를 처리할 수 있다는 것이다.
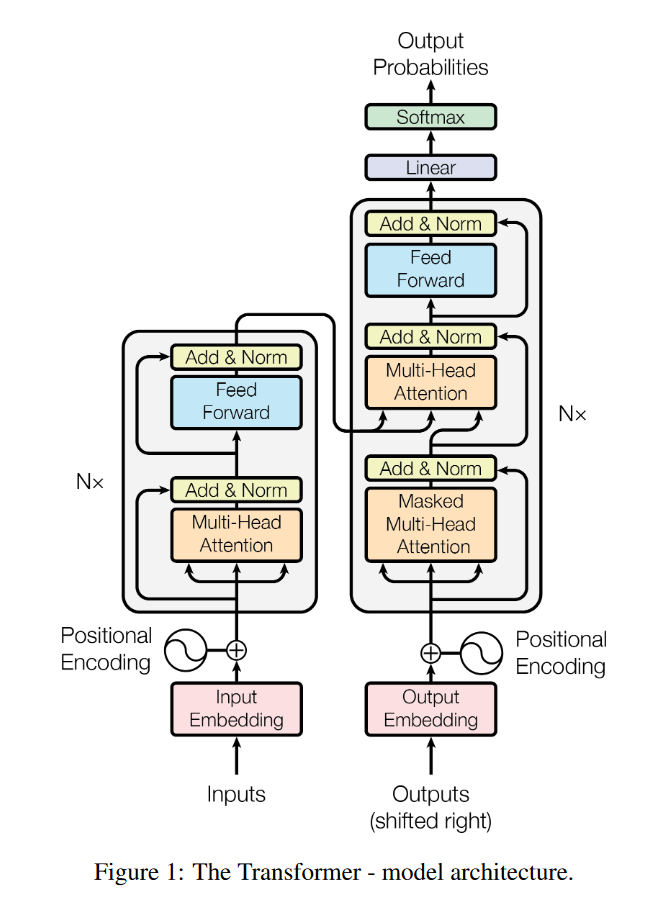

Feed Forward 네트워크와 Attention은 모두 한 번에 병렬로 처리가 가능하다. 그런데 그렇다면 CNN에 대해서는 어떤 장점이 있을까? CNN은 레이어가 증가할수록 수용장(Receptive field)가 증가하는 구조다. 즉 먼 거리의 원소들 사이의 관계를 반영하기 위해서는 그만큼 깊은 레이어가 필요하다. 그러나 주의 메커니즘은 기본적으로 한 번에 시퀀스 내의 원소들에 접근하는 구조다. 즉 시퀀스 내에 있는 모든 원소들을 거리와 관계 없이 다룰 수 있는 것이다.
트랜스포머는 등장 이후 온갖 자연어 처리 및 시퀀스 처리 문제에서 SOTA를 찍기 시작했다. 그러니 프리트레이닝, 전이 학습과 같은 문제에 쓰지 않을 이유도 없었다.

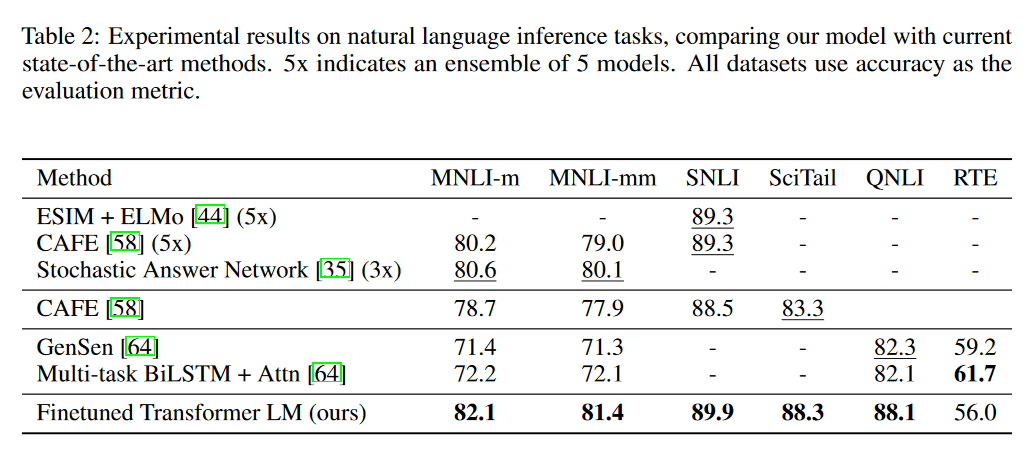
상당히 큰 모델이기 때문에 (Attention 차원 768, FFN 차원 3072, 레이어 수 12) GPU 8개로 한 달 트레이닝을 해야 했지만, 어쨌든 어떻게든 트레이닝을 시킨 모델이 있으면 다른 작업에 학습시키는 건 비교적 용이하다.
그리고 2018년이 이 주제로 뜨거웠던 만큼 이런 방향으로 전이 학습에 적절한 모델을 만드려는 연구들은 여럿 있었다. GLoMo: Unsupervisedly Learned Relational Graphs as Transferable Representations, Representation Learning with Contrastive Predictive Coding 같은 논문들이 떠오르는데 재미있으니 읽어보시면 된다.
마지막으로, BERT
이제 마지막으로 이 글의 목표였던 BERT에 대해 이야기해볼까 한다.
언어 모델은 지금까지 좋은 성능을 보여줬지만 한 가지 큰 문제가 있었다. 언어 모델은 기본적으로 단방향이다. 즉 앞에서 뒤로 간다거나 뒤에서 앞으로 가는 식이라는 것이다. 즉 $t-1$ 시점에서 $t$ 시점의 단어를 예측하는 모델은 $t-1$까지의 이전 단어들의 정보를 사용해야지 $t+1$ 시점의 단어를 사용할 수는 없는 것이다. 이는 언어 모델이 시퀀스의 확률 분포를 순차적으로 분해하는 방법에서 기인한다는 것을 생각하면 자연스러운 일이다. (그리고 흔히 언어 모델을 사용하는 단어를 하나씩 생성하는 경우를 생각해보자. $t$ 시점의 단어를 생성하려는 시점에서 $t+1$ 시점의 단어 정보를 사용하게 만들기는 어렵다.)
이는 분명한 제약이다. 위에서 봤듯 단어의 의미는 그 주위 단어, 즉 양방향의 단어들을 고려할 때 보다 정확히 파악할 수 있다. ELMo는 그래서 앞에서 뒤로 가는 언어 모델과 반대로 뒤에서 앞으로 진행하는 언어 모델을 결합하는 방법을 취했다. 그러면 양방향의 정보를 반영할 수 있겠지만...분리되어 있는 단방향 모델을 비교적 단순하게 결합하는 방식을 취했기에 한계가 있었다.
그러나 자연어 번역 같은 과제에서 디코더는 이런 제약이 있지만 인코더에는 이런 제약이 없다는 것을 알 수 있다. 인코더는 어떻게든, 모든 단어들을 잘 사용해서 문장에 대한 좋은 표현(Representation)을 생성하면 된다. 그렇다면 그렇게 생성된 표현이 언어 모델로 생성된 표현보다 더 나을 수도 있다. 인코더를 학습시키는 것처럼 프리트레이닝을 할 수는 없을까?
BERT는 바로 이 문제를 해소할 수 있는 방법(과 왕창 큰 모델의 사용)으로 성능을 향상시켰다.
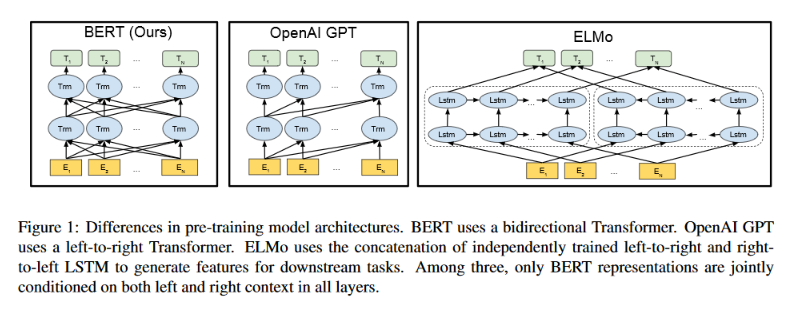
우선, $t$ 시점의 단어를 예측하는 과제에는 $t$만 제외하면 의미있는 학습을 하는데 문제가 없다. $t$가 주어지면 $t$를 복사해서 출력하면 되는 과제가 되어버리니까 의미가 없지만, $t$를 제외하고 주위 단어들로 $t$를 예측하게 하면 결과적으로 주위 모든 단어를 사용해 $t$를 예측하는 과제가 되는 것이다. 즉 $t$를 마스크로 덮어씌우거나 혹은 아예 다른 단어로 대체한 다음 $t$를 예측하도록 학습시키면 된다.
이는 word2vec의 CBOW와 비슷하다고 볼 수도 있고, 또한 이런 식으로 단어를 바꿔친다거나 지운다거나 해서 더 나은 표현을 만드는 방법은 Learning Distributed Representations of Sentences from Unlabelled Data와 같은 논문들에서도 쓰였다. 그러한 방식들이 맥락을 반영하는 언어 표현을 학습하기 위한 최근의 노력들과 결합하니 강력한 결과가 나타난 것이다.
또한 많은 벤치마크 과제는 두 문장을 주고 두 문장의 관계에 대한 정보를 사용해 결과를 내도록 요구한다. 예를 들어 QA 과제의 경우에는 지문을 가지고 질문에 대한 답을 내기를 요구하고, SNLI 같은 자연어 추론 문제는 두 문장을 주고 문장이 모순되는가 등을 묻는다. 즉 문장 사이의 관계를 반영하는 것이 큰 도움이 된다.
문장 사이의 관계를 반영하는 것이 중요하다는 것은 잘 알려진 사실이다. 이러한 문장 간의 관계를 사용하는 접근은 문장의 임베딩 벡터를 생성하기 위해 Skip-Thought Vectors와 같은 모델에서 사용되기도 했다. Skip-Thought Vector의 핵심은 하나의 문장을 입력으로 주고, 그 문장 입력으로 그 문장 이전에 나온 문장과 그 문장 다음에 나온 문장을 생성하도록 하는 것이다. 즉 문장 사이의 맥락적 정보를 사용해 문장의 의미를 반영하는 벡터를 생성하는 것이라고 할 수 있다. 이런 식으로 문장 내의 관계 뿐만 아니라 문장들의 관계와 문서 내의 관계가 중요하다는 것이 밝혀질수록 Wikipedia 코퍼스나 BookCorpus와 같이 문장의 순서 정보가 그대로 보존되어있는 데이터의 인기가 높아지기 시작했다.
그렇지만 문장을 생성하게 하는 방식의 학습은 상당히 비싸기 때문에(모든 단어를 예측하는 과제이기 때문에 그렇다.) 이 과제를 대체하기 위한 접근도 고안됐다. 예를 들어 다음 문장을 생성하게 하는 대신 문장 A와 문장 B를 주고 문장 B가 문장 A 다음에 나올지를 예측하게 하는 것이다. 16
BERT 또한 바로 이런 접근을 사용했다. OpenAI의 GPT와 같이 두 문장을 연결해서 입력으로 주고 B 문장이 A 다음에 나왔을지를 예측하게 하는 것이다.
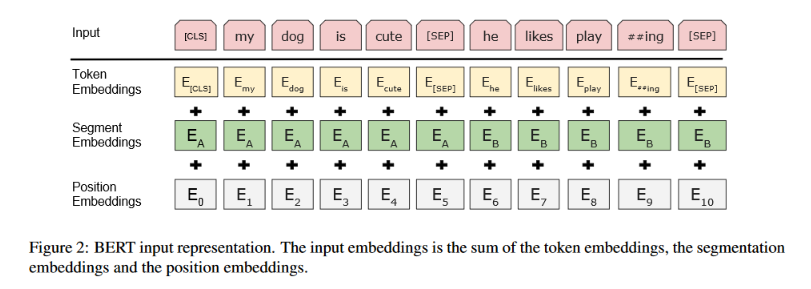
여기에 몇 가지 개선들이 더 들어간다. GPT와는 달리 구분자도 프리트레이닝 과정에서 학습하도록 하고, 왼쪽 문장 A와 오른쪽 문장 B가 다른 문장이라는 것을 표시하는데 도움이 될 수 있는 임베딩을 추가로 학습해주는 것이다. 그리고 파인튜닝을 할 때는 모델 파라미터 전체를 학습시킨다.
이 정도를 한 다음 Wikipedia 코퍼스와 BookCorpus를 결합한 대충 30억 토큰 정도 되는 데이터셋에 TPU 칩 16개를 동원해서 화끈하게 4일 학습시키면 된다. TPU 16개를 썼기 때문인지 GPU 8개를 쓴 OpenAI GPT가 한 달 걸렸던 것에 비해서는 훨씬 빠르긴 하다.

그 결과 이 글을 읽고 계신 분들이라면 다들 아시는 대로 한바탕 벤치마크 깨기를 했다.
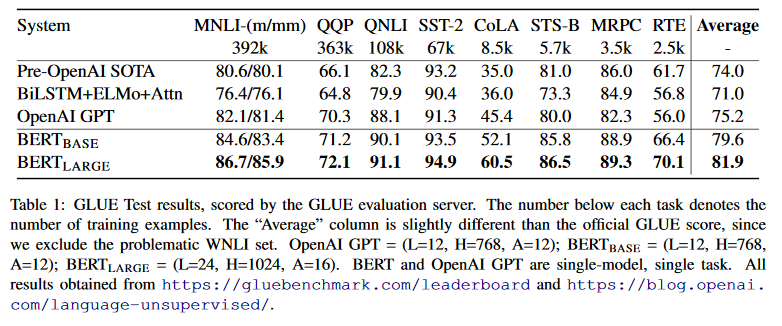
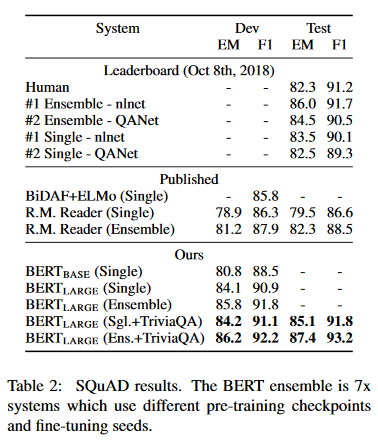
여전히 자연어 처리에 대한 프리트레이닝과 표현 학습(Representation Learning), 그리고 전이 학습은 흥미로운 문제들이 많이 남아있는 문제이고 이미 아주 잘 작동한다는 것이 밝혀진 이상 많은 관심이 모이리라는 것은 자명하다. 그리고 공학적인 입장에서도 넘쳐나는 텍스트 코퍼스를 활용해 수많은 자연어 처리 과제의 성능을 높일 수 있다는 건 흥분을 넘어 상당히 행복한 일이다.
마무리, 그리고 자연어의 의미를 이해한다는 것
언어학이나 발달심리학에 대한 지식이 일천하지만, 다들 자연어의 의미 학습, 자연어 이해 같은 표현을 쓰는 상황에서 자연어를 이해한다는 것이 무엇인지, 자연어의 의미란 무엇인지에 대해 생각해보지 않을 수 없다.
물론 의미라는 것이 무엇인지, 이해한다는 것은 무엇인지 같은 것은 파고들면 아주 어려운 철학적 문제에 도달하게 될 것이다. 어쩌면 그 문제는 답이 없는 것인지도 모른다.
그렇지만 좀 더 생각해보려고 한다. 언어 모델은 정말 앵무새처럼 - 이는 물론 앵무새를 비하하려는 것은 아니다 - 자연어를 흉내내고 있을 뿐인 것은 아닐까?
언어의 의미는 세계에 대한 정보 등의 맥락적인 정보 등을 통해 결정되는 것으로 보인다. 그러나 우리의 모델에게는 그런 디테일하고 품질 높은 정보는 잘 주어지지 않는다. 인간은 언어를 주위 사람들의 끊임 없는 언어 사용과 피드백을 통해 배운다. 예를 들어 이 대상을 가리킬 때는 이 단어 대신 저 단어를 사용해야 한다든가, 혹은 문장을 구성하기 위해서는 단어를 어떠어떠하게 배치해야 한다든가 하는 피드백이 주어진다. 우리에게도 이런 피드백을 줄 수 있는 언어 시뮬레이터가 있으면 좋겠지만, 그런 시뮬레이터를 만들 수 있다면 애초에 언어 모델을 학습할 필요가 없을 것이다.
대신 우리에게는 실제로 사용된 언어의 흔적들인 말뭉치, 코퍼스가 주어진다. 언어 모델의 경우를 생각해보면 세계에 대한 정보나 맥락에 대한 정보는 이전에 등장했던 단어들이 제공한다. 즉 이전에 등장했던 단어들이 합쳐져 세계와 화자의 의도에 대한 맥락을 제공하는 것이다. 또한 어떠한 단어를 어떻게 사용해야 하는지에 대해서 코퍼스는 실제로 단어를 어떻게 사용했는지에 대한 사례가 된다.
언어 모델만으로 사과 7개가 있었는데 2개를 먹었다. 그러면 남은 사과는 몇 개? 라는 질문에 대해 5개라고 대답하게 만들기는 어려울지도 모른다. 그러나 충분한 코퍼스로 잘 학습시킨다면 이러한 질문 뒤에 숫자가 나와야 한다는 것은 학습할 수 있을지도 모른다. 사람도 구체적인 계산을 틀리는 경우는 종종 있지만 숫자를 묻는데 전혀 엉뚱한 대답을 하는 경우는 없지 않은가?
물론 실용적인 입장에서는 이런 문제에 대한 생각을 할 필요는 없다. 수많은 자연어 처리 과제에서 좋은 성능을 낸다는 것은 문법적인 정보든 의미적인 정보든 잘 표현하고 있다는 의미가 아니겠는가? 아니 그러한 정보를 표현하고 있는가 어떤가를 생각할 필요도 없다. 일단 잘 되면 된다!
- Semi-supervised Sequence Learning (2015) [return]
- Universal Language Model Fine-tuning for Text Classification (2018) [return]
- SQuAD: 100,000+ Questions for Machine Comprehension of Text (2016) [return]
- Convolutional Neural Networks for Sentence Classification (2014) [return]
- WaveNet: A Generative Model for Raw Audio (2016) [return]
- Neural Machine Translation in Linear Time (2016) [return]
- Convolutional Sequence to Sequence Learning (2017) [return]
- Recurrent Continuous Translation Models (2013) [return]
- Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation (2014) [return]
- Neural Machine Translation by Jointly Learning to Align and Translate (2014) [return]
- A Neural Network for Machine Translation, at Production Scale [return]
- Long Short-Term Memory-Networks for Machine Reading (2016) [return]
- A Structured Self-attentive Sentence Embedding (2017) [return]
- Attention Is All You Need (2017) [return]
- Improving Language Understanding by Generative Pre-Training (2017) [return]
- An efficient framework for learning sentence representations [return]

