텔 아비브와 ECCV 2022 여행기 4
- 텔 아비브와 ECCV 2022 여행기 1
- 텔 아비브와 ECCV 2022 여행기 2
- 텔 아비브와 ECCV 2022 여행기 3
- 텔 아비브와 ECCV 2022 여행기 4
- 텔 아비브와 ECCV 2022 여행기 5
- 텔 아비브와 ECCV 2022 여행기 6
- 텔 아비브와 ECCV 2022 여행기 7

본격적인 학회의 시작. 학회는 텔 아비브 엑스포에서 진행됐다.

엑스포 건물 앞에는 이렇게 널부러져(?) 있을 수 있는 공간이 있었는데 텔 아비비의 햇볕은 사실 파라솔 하나 정도로는 버티기 어려운 감이 좀 있었다. 각도가 딱 맞으면 모를까.


첫 발표는 Long-Tail Detection with Effective Class-Margins. 이쪽은 포스터에서 약간 질의를 나눴으므로 그쪽에서 소개하기로.

사진이 없어서 좀 건너뛰고 다음은 Improving Robustness by Enhancing Weak Subnets. 예를 들어 Lottery Ticket이 있다면 Lottery Ticket 외의 나머지 Weight들의 역할은 무엇인가? 이 Weight들이 구성하는 Sub Network들의 성능을 확보하는 것이 Robustness에 도움이 될 수 있다는 아이디어. 단 이 Weak Subnet을 찾는 것이 그렇게 쉬운 작업은 아닌 듯 하고 여기서는 RL/Policy Gradient를 사용했다.

다음은 Monocular 3D Object Detection with Depth from Motion. 이쪽은 제목 그대로 Monocular 3D Object Detection을 다루는데 Monocular Detection에서 성능을 제약하는 가장 큰 요인은 Depth 정보의 불충분함이라는 아이디어였다. 카메라의 움직임을 통해서 수집된 이미지들을 통해 이 Depth 정보를 추정하는 것으로 성능을 향상시킬 수 있다는 연구.

포스터 발표장으로. 이스라엘 아니랄까봐 Rafael이라는 군수기업 부스도 하나 있었다. 웬 미사일 런처가 하나 있었는데 한 번씩 메어보는 사람들이 있었음. 대충 미사일 런처로 비행 표적을 조준하는 시뮬레이션 같은 것이었던 듯.

Springer에서 여는 학회답게 Springer 책도 팔고 있었다.

Weights & Biases 부스. 네이버 클로바에서 왔다고 하니 알아보더라. 아주 잘 쓰고 있다고 한 마디 했다. 뭔가 개선을 원하는 것이 있냐는 질문도 있었는데 내가 쓰는 레벨에서는 딱히 개선의 필요가 느껴지는 것은 없어서 고민을 좀 했다. (결국 말은 안 함.)

자율주행 관련해서 나온 부스도 좀 있었다. GM이나 Mobileye 등.
CV에 남은 것은 무엇인가? 학회장에서 한국 사람들과 만나면서 CV에 남은 주제는 1. Multimodal, 2. Generation (Diffusion), 3. 3D (Implicit Representation) 이라고 요약하는 패악질(?)을 부렸다. 그런데 생각해보면 여기에서 Video에 대한 언급을 깜박한 듯. 특히 학회장에서 눈에 종종 띈 것이 역사와 전통의 트래킹 문제.
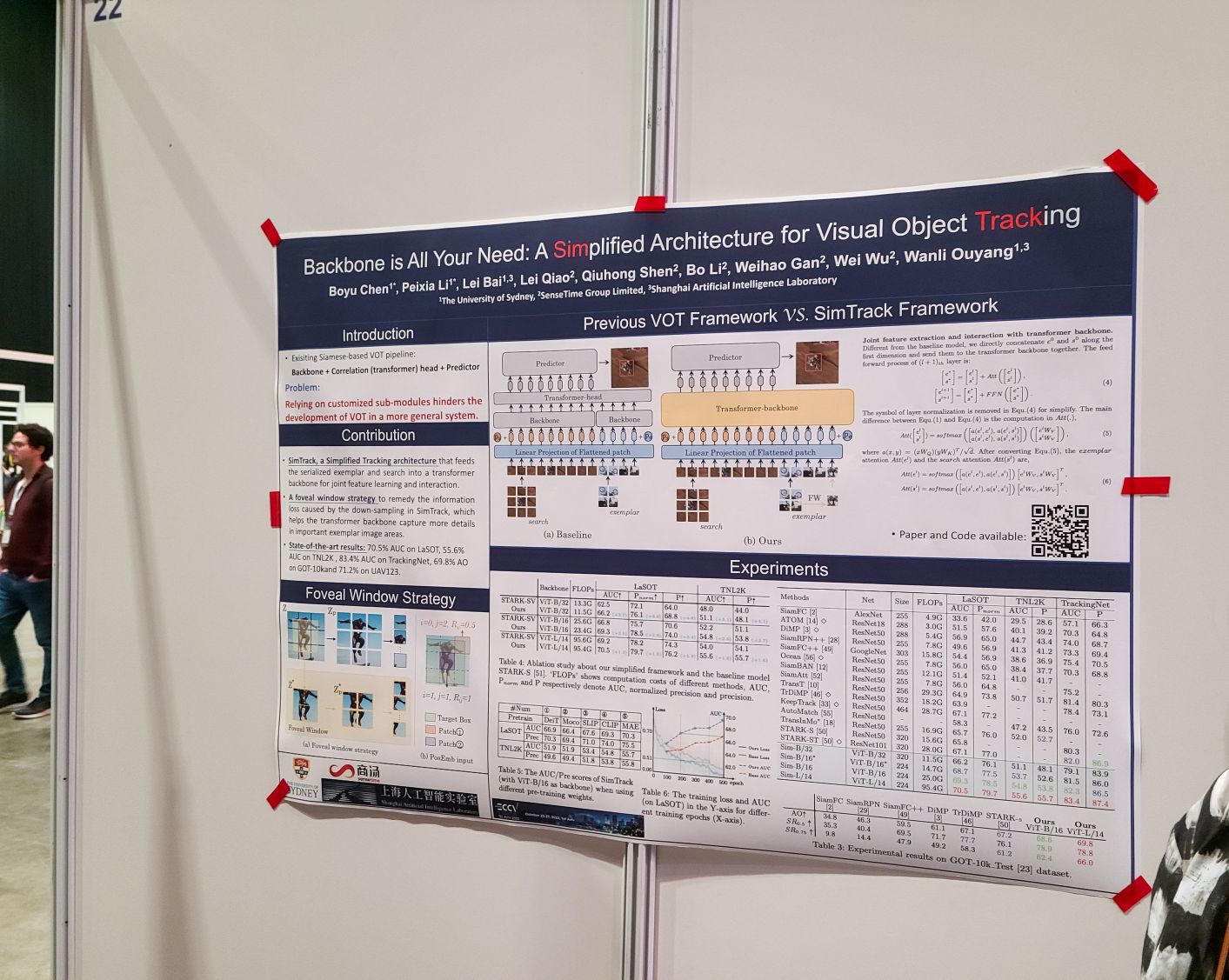
Backbone is All Your Need: A Simplified Architecture for Visual Object Tracking. 서치 이미지와 예제 이미지, 그리고 예제 이미지의 중앙 부분 크롭을 트랜스포머에 집어넣고 결과를 내놓도록 만들면 된다는 아이디어.
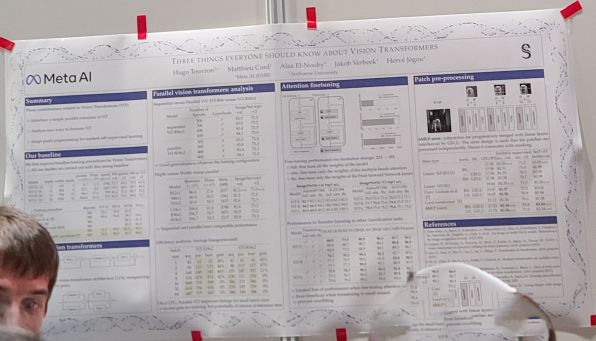
Three things everyone should know about Vision Transformers
1저자 Hugo Touvron을 여기서 처음 보게 됐다. 워낙 인기가 있어서 질문이 어려웠던지라 내용은 이전에 기록해둔 노트로 대체.
- y = x + mhsa(x), z = y + ffn(y) 같은 방식으로 계속 쌓는 대신 y = x + mhsa(x) + mhsa(x), z = y + ffn(y) + ffn(y) 같은 식으로 모듈들을 병렬로 (약간 multi branch스럽게) 결합할 수 있다. 계산도 병렬로 잘 하면 더 빨라질지도? 입니다. gpt-j에서 y = x + mhsa(x) + ffn(x) 같은 접근을 사용한다던데 비슷한 것 같기도 하네요.
- 파인튜닝 할 때 (특히 입력 크기가 달라질 때) mhsa만 튜닝해도 충분하다.
- stride 16 patchify 레이어를 더 작은 stride를 가지는 patchify 레이어들로 쪼개는 것도 괜찮다(resnet-d 스럽게) 입니다.

오랄 발표였던 Long-Tail Detection with Effective Class-Margins. 학습 목표와 테스트 mAP 메트릭 사이에는 갭이 있으므로 mAP의 바운드에 해당하는 에러로 학습한다는 아이디어이다. 결과적으로는 Long-Tail 검출 문제에 이전에 적용되어왔던 방식, 예를 들어 Seesaw Loss (https://arxiv.org/abs/2008.10032) 같은 것처럼 loss를 reweighting하는 것과 비슷한 결과가 된다. 그렇지만 장점이라면 이 loss에 대해 추가적인 하이퍼파라미터가 요구되지 않고 loss 그대로 최적이라는 부분. 저자의 설명으로는 이전의 접근들도 대체 왜 되는 것인지 좀 이해가 되지 않는 부분이 있는데 (예를 들어 loss reweighting만으로 long-tail 문제가 풀린다고? 라는 근본적인 질문), 그렇다면 그 이해가 되지 않는 접근을 완결할 수 있는 접근을 고안하겠다는 방향이었다는 것 같다.

오랄 발표였던 Multimodal Object Detection via Probabilistic Ensembling. 예를 들어 RGB 이미지와 Thermal 이미지 같은 Multimodal 세팅에서 각 이미지에 대해 각각 나온 검출기의 검출 결과를 어떻게 조합할 것인가 하는 문제. 기본적인 접근은 $p(y|x_1)$과 $p(y|x_2)$가 있을 때 $p(y|x_1,x_2)$를 추정하는 문제로 보는 것. 늘 그렇듯이 베이즈 룰을 동원해서 태클하는 접근이었다. 그렇다면 Multimodal 뿐만 아니라 일반적인 디텍션 앙상블을 위해서도 쓸 수 있는가? 질문했었는데 그렇다고 한 것 같긴 하다. (오랄 상황에서 했던 질문이라 응답이 아주 정확한 것이었는지 좀 애매하다. 그렇지만 안 될 이유는 없지 않을지.)

ECCV 2022 최고 스타였던 Jingkang Yang (https://twitter.com/jingkangy)의 Panoptic Scene Graph Generation. 저 LED 백팩을 보면서 다음에 논문 홍보를 할 일이 있다면 저걸 꼭 구해놓겠노라고 다짐했다. 여하간 논문 주제는 일반적인 Scene Graph 같이 바운딩 박스 상황에 대한 그래프 출력이 아니라 Panoptic Segmentation 출력에 대한 Scene Graph 생성 문제였다. 내가 질문했던 것은 포스터에도 나와있는 PSGTR과 PSGFormer의 차이. PSGTR은 Scene Graph의 Triplet (Subject/Predicate/Object)를 모두 포함하는 쿼리가 사용되고 PSGFormer는 Object 쿼리와 Relation 쿼리로 factorize 되어있다. 학습은 PSGFormer가 더 빠르지만 성능의 바운드는 PSGTR이 높다.
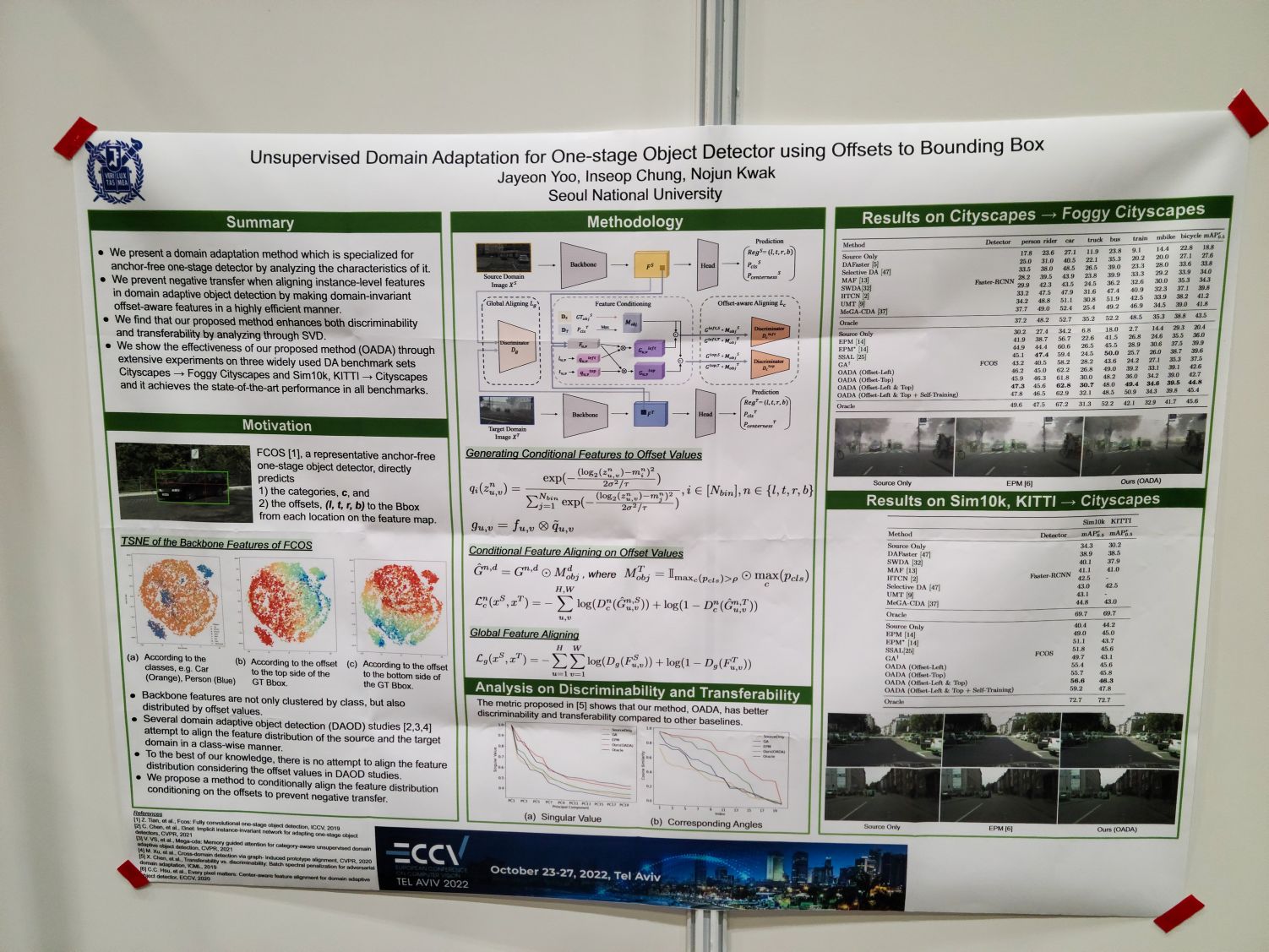
Unsupervised Domain Adaptation for One-stage Object Detector using Offsets to Bounding Box. FCOS 같은 디텍터에서 나오는 출력 feature들은 class 뿐만 아니라 offset에 따라서도 분화되어 있는데 domain adaptation에서 이 오프셋에 따른 feature clustering을 고려해 수행한다는 아이디어인 듯. 각 feature level마다 부여되는 box scale이 다른데 그 부여된 scale 내에서 이러한 offset별 분화가 관찰된 것인가 하는 질문을 했었는데 상황이 어수선해서 답은 제대로 확인하지 못했다. 그렇지만 생각해보면 당연한 소리를 질문으로 한 듯.

Streamable Neural Fields. Implicit Representation은 다른 포맷들, 예를 들어 일반적인 영상이나 음성 파일과는 달리 파일의 일부만으로는 reconstruction이 불가능하고 전체 weight가 필요하다. 그렇다면 일반적인 영상이나 음성 파일처럼 일부 weight만으로도 점진적인 reconstruction을 할 수 있는 implicit representation을 학습시킬 수 있는가? 하는 주제. 약간 상상도 해보지 않았던 주제라 흥미로웠다.
이외에 눈에 띄었던 포스터들.



학회장 한쪽에서는 이런 강연을 하고 있었다. 이어폰을 쓰면 들을 수 있는 식. 주제는 요즘 가장 뜨거운 문제 Text to Image Generation.
강연 스케줄.

점심 타임. 슈니첼과 가지와 빵. 슈니첼이 학회 단골 메뉴였다.







전 직장 동료라거나 같은 회사 분이라거나 혹은 대학 연구실의 연구자들 등등의 한국인들을 만나 뱃지 인증.


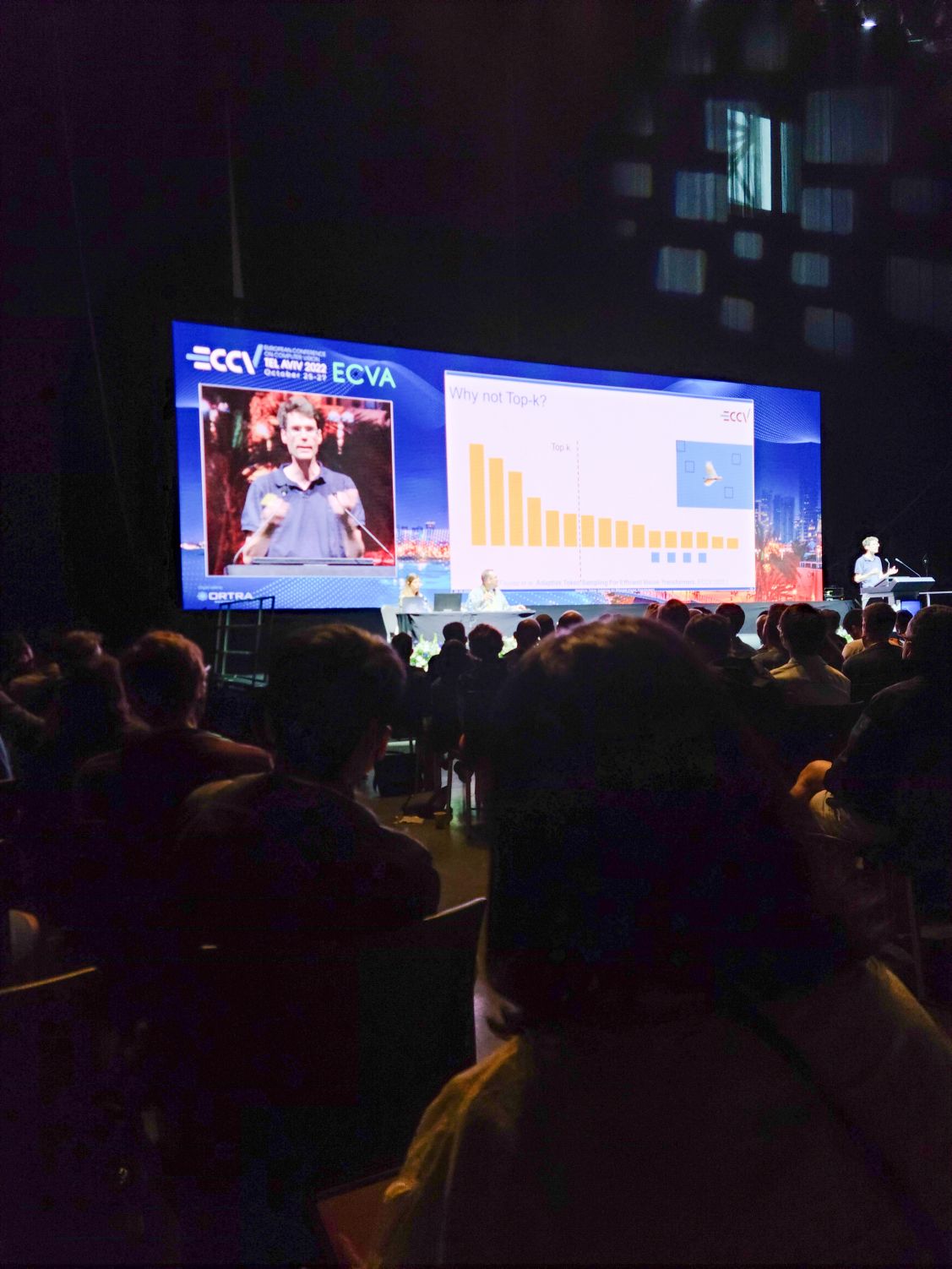
오후 발표. Adaptive Token Sampling For Efficient Vision Transformers. 포스터에서는 인기가 너무 많아서 질문할 여유가 없었다. ViT에서 토큰이 전부 다 필요해? 라는 문제 의식에서 나오고 있는 연구들 중 하나라고 할 수 있겠다. attention weight와 embedding norm을 사용해 스코어를 구하고 (norm이 낮으면 결과에 영향이 적다는 부분을 추가로 고려한 것이라 할 수 있겠다.) top-k 대신 스코어를 사용해 inverse transform sampling으로 토큰을 뽑아낸다. 스코어가 낮은 토큰이 선택되는 경우가 생긴다는 점, 그리고 같은 토큰이 두 번 선택되는 경우 두 토큰을 하나로 합치는 것으로 결과적으로 샘플 수 $k$보다 작은 수의 토큰을 사용하도록 할 수 있다는 점이 선택의 이유.


The Challenges of Continuous Self-Supervised Learning. 지금까지 self supervised learning은 고정된, 큐레이션된 데이터셋에 대해서 성공적이었음. 그러나 데이터가 계속적으로 추가되고, 데이터 샘플들 사이에 correlation이 있으며, 데이터 분포가 계속적으로 변화하는 상황이라면 어떨까? 이 경우 가장 큰 무기는 리플레이 버퍼. 리플레이 버퍼를 사용하는 것으로 이 특징들에서 발생하는 문제들을 상당히 경감할 수 있다는 연구.

PACTran: PAC-Bayesian Metrics for Estimating the Transferability of Pretrained Models to Classification Tasks. 포스터에서 저자와 잠깐 이야기할 수 있었으니 그쪽에서.

Towards Sequence-Level Training for Visual Tracking 이번 학회에서 트래킹 하시는 분들을 만나서 조금씩 이야기를 들어볼 수 있었는데, 트래킹에서는 아직 sequence level로 학습하는 사례는 이제 막 나오는 시점인 모양. 시퀀스 단위가 아니라 프레임 단위로 학습하는 것으로 인해 occlusion 등이 발생했을 때 놓치는 사례를 방지하기 위해 시퀀스 단위로 트래킹을 학습한 사례라고 할 수 있겠다. 이 시퀀스 레벨 학습을 위한 핵심 컴포넌트가 REINFORCE를 사용한 강화학습이길래 학습이 잘 되냐고 물어봤는데 저자의 응답으로는 하이퍼파라미터를 잘 맞추면 되긴 된다고. 😅
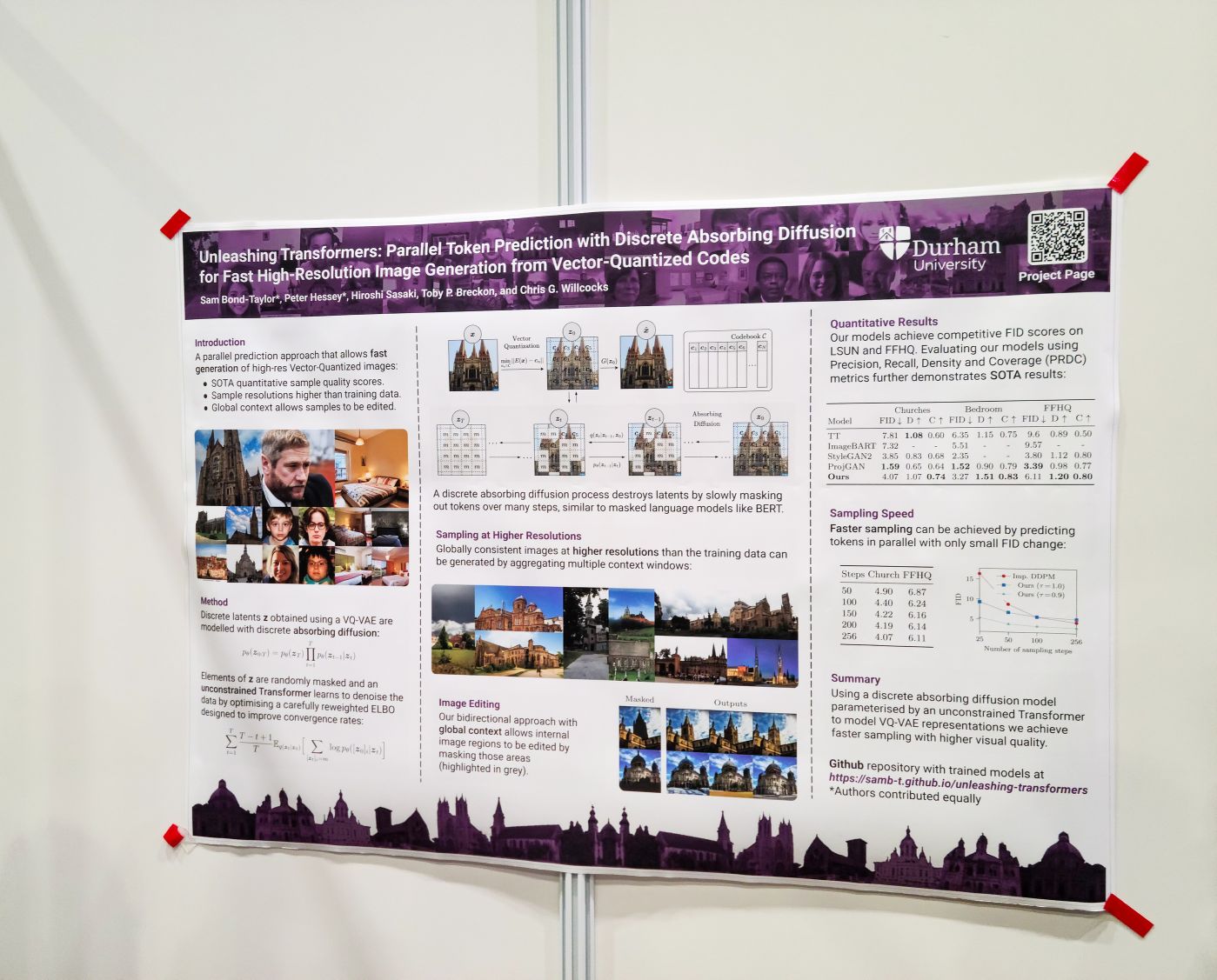
Unleashing Transformers: Parallel Token Prediction with Discrete Absorbing Diffusion for Fast High-Resolution Image Generation from Vector-Quantized Codes. 바로 생각나는 게 MaskGIT (https://arxiv.org/abs/2202.04200)이라서 저자들에게 MaskGIT과 어떻게 다른지 물어보니 사실 비슷한 시점에 나온 비슷한 연구인 것은 맞다는 의견. (시점으로는 Unleashing Transformers가 먼저 나왔다.) 차이로 제시한 것은 샘플링 과정. MaskGIT은 스코어 기반으로 토큰을 샘플링했는데 이후 코드를 확인해보니 Unleashing Transformers는 랜덤하게 생성할 토큰을 샘플링한다.
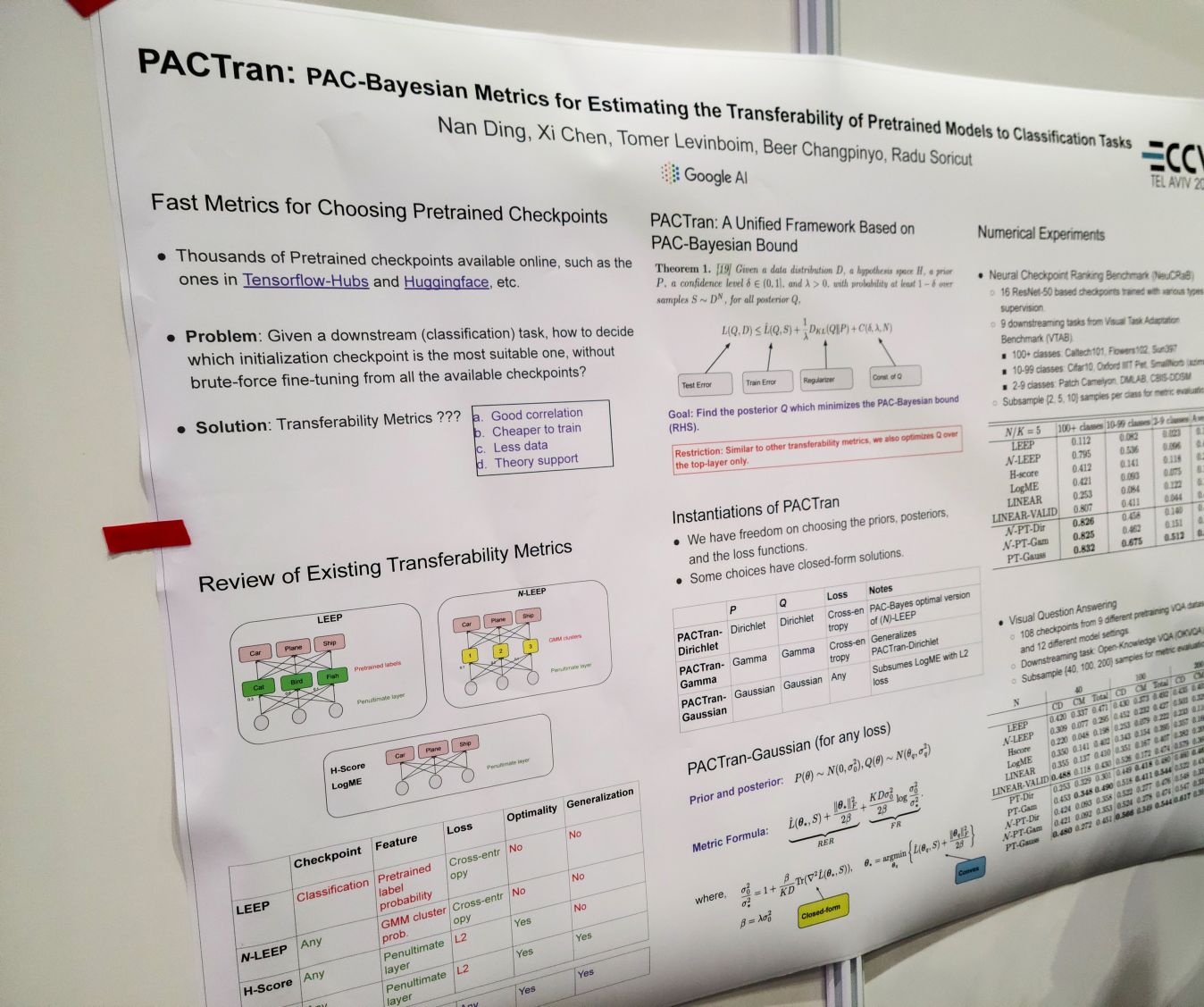
PACTran: PAC-Bayesian Metrics for Estimating the Transferability of Pretrained Models to Classification Tasks. 파인튜닝을 해서 성능을 찍어보기 전에 모델 weight가 각 과제들에게 잘 transfer 될 수 있는지를 평가하는 메트릭을 만들 수 있을 것인가 하는 과제. 직관적인 레벨에서 다루자면 PACTran은 최종 레이어의 출력의 파인튜닝 데이터에 대한 학습 loss와 flatness/smoothness의 결합으로 transferability를 평가한다고 할 수 있는 것 같다. flatness는 generalizability에 대해 계속해서 유용하다는 사례들이 나오는 것 같다. 혹은 반대로 우리가 가지고 있는 척도가 그것 정도 밖에 없다는 의미일 수도 있겠고.

An Impartial Take to the CNN vs Transformer Robustness Contest. 이전 메모에는 또 이렇게 대충 써놨다.
cnn (convnext) vs vit의 robustness, calibration, ood detection 등에 대한 성능 분석. cnn이 나은 경우도 있고 vit가 나은 경우도 있고 전반적으로 엇비슷하다는 것이 결론이네요.
ViT가 CNN보다 더 robust하다는 주장에 대해 ConvNeXt 이후로 CNN과 ViT가 비슷한 robustness를 보일 수 있다는 것을 보인 연구라고 할 수 있겠다. self attention vs conv 둘 중 하나가 더 robust함을 가져오는 것은 아니고, vit도 똑같이 simple한 feature에 대한 선호가 있다는 것 등을 보였다. 결국 self attention이냐 conv냐가 아니라 학습 방식이나 layer norm 등의 존재가 더 큰 영향을 미친다는 의미인데, 두 아키텍처의 가장 두드러지는 차이가 아닌 미묘해보이는 차이들이 이런 특성을 만든다는 결론이라 시사하는 바가 있는 듯 싶다. 과장해서 말하자면 결국 우리는 아직도 normalization의 효과가 무엇인지 모른다고 할 수 있겠다.
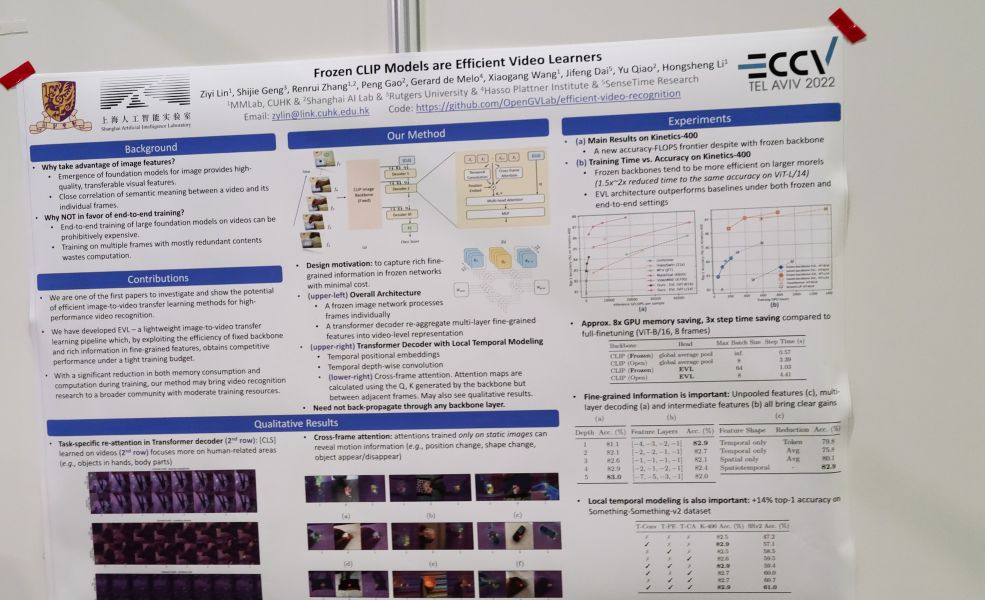
Frozen CLIP Models are Efficient Video Learners. 얼려놓은 CLIP feature에 대해 temporal modeling을 결합하고 cls token에 대한 attention으로 cls token 임베딩을 업데이트해나가는 방식으로 비디오 분류. 심플!
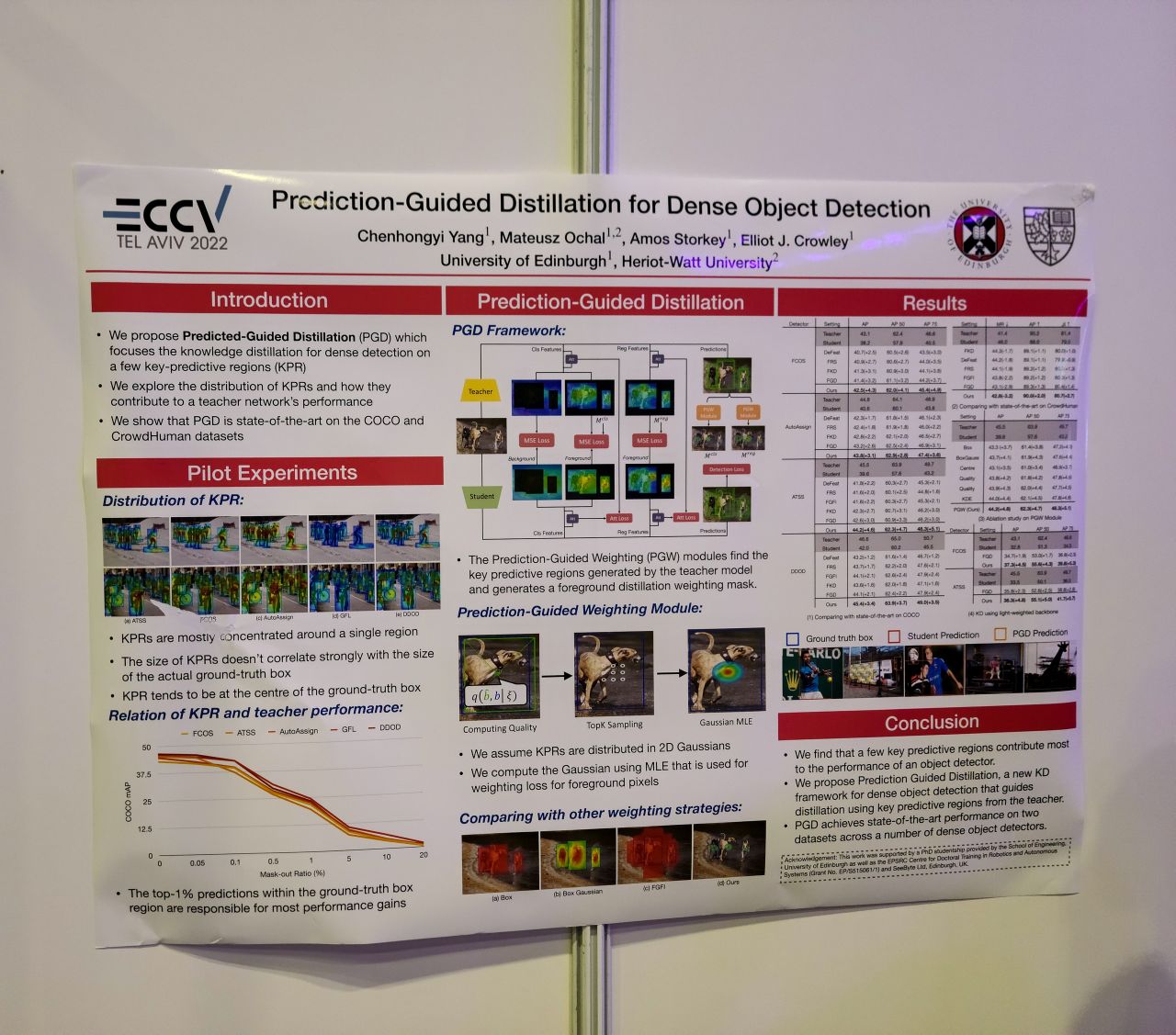
Prediction-Guided Distillation for Dense Object Detection. 객체 검출기에서 confidence가 높은 영역, 즉 박스 예측에 주로 관여하는 영역은 한정되어 있는데 이 영역 정보를 사용해서 distillation 하는 방법. 좀 다르긴 하지만 최근 본 모바일 검출기들에서 모델 출력을 사용해 loss assign을 하는 방법들이 생각났다.

ARF: Artistic Radiance Fields. 이 논문도 여기 나왔다. https://www.cs.cornell.edu/projects/arf/
그 외 또 눈에 띄었던 논문들.


호텔에서 5시 반 ~ 7시 정도까지 해피 아워가 있어서 잠깐 와인을 한 잔.

왜 음식 사진이 없지!?
이 날 저녁은 Little Prague에서. 바로 앞에 중동 음식점이 있었는데 유명하긴 한지 학회 참가자들까지 밀려와서 웨이팅이 있어 포기. (다음에도 한 번 더 가봤는데 여전하더라.) 내 픽은 거위 다리 구이. 그럭저럭 괜찮았다.

