텔 아비브와 ECCV 2022 여행기 5
- 텔 아비브와 ECCV 2022 여행기 1
- 텔 아비브와 ECCV 2022 여행기 2
- 텔 아비브와 ECCV 2022 여행기 3
- 텔 아비브와 ECCV 2022 여행기 4
- 텔 아비브와 ECCV 2022 여행기 5
- 텔 아비브와 ECCV 2022 여행기 6
- 텔 아비브와 ECCV 2022 여행기 7

카푸치노와 함께한 아침.

전혀 안 어울리는 조합이지만 샥슈카가 꽂혀서 이런 괴상한 짓도 해봤다.






이 날은 비가 왔다. 많이 내리지는 않을까 싶었는데 잠깐 내리다가 그쳤다.
3D-Aware Indoor Scene Synthesis with Depth Priors. NeRF rendering에 의존하지 않고 3D 생성 모델 구성하기 1. 이쪽은 depth 정보를 활용하는 방향이다. generator에서 depth 또한 생성하게 만들고 discriminator에 depth 입력을 사용하고 또한 rgb에서 depth를 예측하게 만드는 방식. depth는 depth estimation으로 추출해서 사용하는 paired 세팅.

Generative Multiplane Images: Making a 2D GAN 3D-Aware. NeRF rendering에 의존하지 않고 3D 생성 모델 구성하기 1. 이쪽은 포스터 파트에서 소개.

How stable are Transferability Metrics evaluations?. 파인튜닝 없이 모델 weight 체크포인트의 성능 순위를 매기는 메트릭들에 대한 벤치마크. 포스터에서처럼 가장 좋은 소스 데이터셋/가장 좋은 아키텍처를 고르는 상황에 따라 더 나은 메트릭이 다르다고. 어제 나온 PACTrans에 대해서는 어떻게 평가하는지 물어봤더니 구글 리서치 내에서도 논문이 쏟아지는 상황이라 그런 연구가 있는지 모르는 상황에서 제출했다고 한다. 혹시 이후에 테스트해보지는 않았는지 물어봤는데 아직이라고. 구글 레벨에서도 더 나은 체크포인트를 파인튜닝 없이 찾아볼 수 있는 연산 효율성이 중요한 것인가 싶기도 하고, 또 다른 의미로는 더 나은 체크포인트를 찾으려고 한다는 것 자체가 흥미로운 부분이다 싶기도 하다.
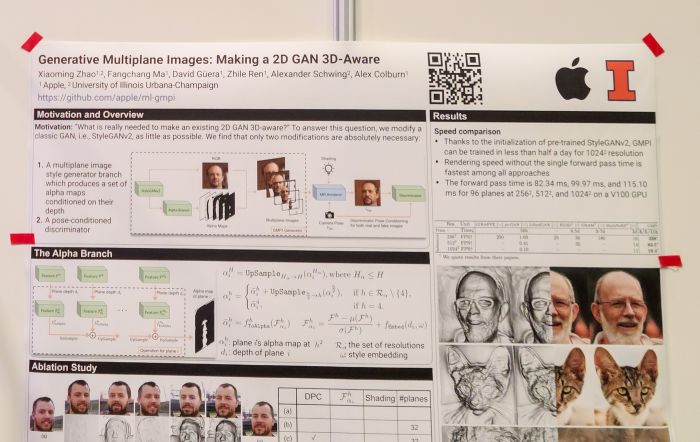
Generative Multiplane Images: Making a 2D GAN 3D-Aware. 2D GAN에서 이미지 하나와 여러 장의 알파 채널 마스크를 생성하게 한 다음 알파 채널과 생성 이미지를 조합해서 multiplane 이미지를 만들고 이 이미지의 조합으로 렌더링된 이미지를 생성하는 3D 생성에 대한 접근. NeRF rendering을 거치지 않으니 샘플링 속도가 빠르다. 어쩐지 성능 스코어 언급이 없어서 물어보니 EG3D와도 경쟁력이 있다고 언급. 다만 논문 스코어를 찾아보니 FID 등이 좀 밀리긴 하는 듯.

FurryGAN: High Quality Foreground-aware Image Synthesis.
생성된 이미지의 배경을 바꿀 수 있는 쉬운 방법 -> foreground 객체에 대한 fine-grained mask를 확보하는 것. 결과적으로 alpha composite로 최종 결과물을 만들 수 있게 foreground, background, alpha mask를 잘 생성하도록 모델에 강조하는 것이 요점. salient object detection으로 풀면 어떤 결과가 나오는지 궁금했는데 시도해보지는 않았다고. 아마도 이 연구 쪽이 더 낫지 않을지?

Vector Quantized Image-to-Image Translation. style-content disentangle과 style/content 교차, consistency를 사용하는 image2image, 거기에 vq-vae content encoding을 사용. 오랜만에 보는 형태의 접근이었다. style-content disentanglement를 강제하는 방법에 대해 물어봤는데 여기서는 adain 사용과 consistency loss 사용으로 대처한 듯.

Text2LIVE. 원본 이미지 + 편집 레이어를 조합하는 식으로 이미지를 편집하는 방법. 원본 이미지와 편집 레이어에 대한 결합을 CLIP 임베딩으로 텍스트와 loss를 걸어 학습시키고, 편집 레이어는 그린 스크린 위에 올린 후 green screen 프롬프트를 추가한 CLIP 임베딩으로 학습. CLIP을 학습시키면서 그린 스크린 이미지도 많이 봐서 되는 것 같다고.

Any-resolution Training for High-resolution Image Synthesis. 여러 해상도의 이미지로 구성된 데이터셋을 집어넣어 학습해도 고해상도의 이미지를 생성할 수 있는 모델. 핵심은 패치를 크롭해서 real sample을 만들고 크롭 파라미터를 generator에 입력으로 주는 것. StyleGAN 3를 기반으로 했다기에 antialiasing에서 이슈가 생길만한 부분은 없었는가 물으니 특별히 문제는 없었다고 한다.

FCAF3D: Fully Convolutional Anchor-Free 3D Object Detection. 포인트 클라우드에 대한 object detection. 포인트 클라우드에 대한 sparse convolution과 rotation parametrization이 주요 기여 포인트.
그 외 눈에 띄었던 포스터들.




간식으로 놓여있어서 하나 집어먹어 봤는데 짜기만 했다.

점심으로 나온 것. 안에 채운 것은 생선살이다. 바닷가라서 그런지 해산물 요리가 많기도 했다. 프레첼처럼 이 메뉴도 학회 단골이었다.

점심 시간에 밖에 나와서 널부러져봄. 그런데 널부러져 있기엔 햇볕이 너무 뜨겁고 좋은 지점은 이미 다 선점한 사람들이 있었다.


이 햇볕을 배경으로 ordinal regression을 연구하는 분과 depth estimation을 연구하는 분을 만나 잠깐 이야기를 했다.
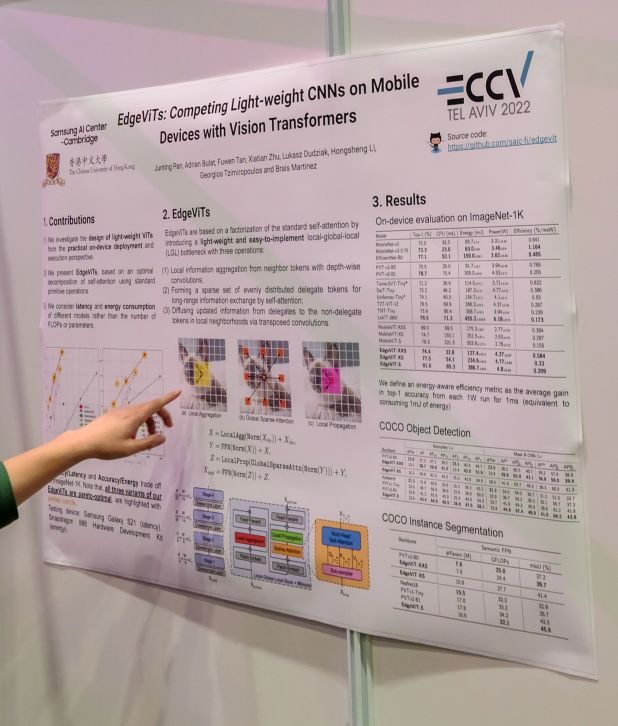
EdgeViTs: Competing Light-weight CNNs on Mobile Devices with Vision Transformers
모바일 지향 ViT. 기본적으로 depthwise conv + pooled attention + transposed conv 조합이다.

TokenMix: Rethinking Image Mixing for Data Augmentation in Vision Transformers. CutMix와 비슷한 느낌인데 하나의 사각형 영역을 잡는 대신 분리된 여러 영역을 잡도록 만들고 학습 타겟 레이블을 mixing ratio로 잡는 대신 teacher network의 activation map의 스코어를 사용해서 할당하는 방법. 다들 activation map을 왜 이렇게 좋아하지!?
별개로 토큰 개념으로 생각하면 CutMix도 좀 특이한 방향으로의 응용을 생각해볼 수 있는 것 같다. 대표적으로 흥미롭다고 생각한 것은 MixMIM (https://arxiv.org/abs/2205.13137) 같은 방법.

What to Hide from Your Students: Attention-Guided Masked Image Modeling. teacher의 activation map를 활용하는 연구가 있는 것처럼 이렇게 teacher의 self attention을 사용해 masked image model의 mask를 생성하는 연구도 있었다.

JoJoGAN: One Shot Face Stylization. 죠죠간까지.
그 다음은 파워 리셉션 시간. 아무래도 리셉션이 학회마다 다르다보니 ECCV에서는 어떤 분위기일지가 화제였는데…대충 이랬다.



이젠 식빵에 끼운 슈니첼 바리에이션이 나왔다.

맛있긴 했음.

이렇게 메가스터디에서 ML을 연구하는 분도 만날 수 있었음. 리셉션에서 기대하는 것이 이렇게 쉽게 만나기 어려운 사람들 사이에 점프하듯 연결을 만들 수 있는 것 아닐까…싶었지만.


본격적으로 공연 & 클럽 분위기로 전환됨.


TARARAM이라는 이스라엘 난타(?)가 등장.

ECCV 체어의 짧은 멘트.

ClearML이 ECCV 2022 스폰서여서인지 ClearML 대표가 나옴.

TARARAM이 한 번 더 나오고,

본격적으로 클럽 시작. 사실 처음에는 약간 민망한 느낌이 들 정도로 정적이었는데 점점 분위기가 바뀜.

분위기가 맞지 않는 사람들이 슬슬 나가고 혼모노들만 남아서인 듯.

ECCV 최고 스타와 그의 백팩이 등장.


중간에 츄러스를 하나 주길래 챙김.


역시 스타는 아무나 되는 것이 아님. 백팩 하나 사는 것으로 흉내낼 수 있다고 생각했던 것을 반성합니다.


마치고 나니 11시가 넘었던 것 같음. 이때 리셉션을 끝까지 보고 있었던 것이 후폭풍을 만들었는데…여하간 이 날은 이것으로 마무리. 호텔로 돌아와 어쩌다 만난 분과 VITON에 대한 성토를 잠깐 한 후 종료.

