텔 아비브와 ECCV 2022 여행기 6
- 텔 아비브와 ECCV 2022 여행기 1
- 텔 아비브와 ECCV 2022 여행기 2
- 텔 아비브와 ECCV 2022 여행기 3
- 텔 아비브와 ECCV 2022 여행기 4
- 텔 아비브와 ECCV 2022 여행기 5
- 텔 아비브와 ECCV 2022 여행기 6
- 텔 아비브와 ECCV 2022 여행기 7
학회 마지막 날.

또 샥슈카를 열심히 챙김.

좀 이상한 타이밍에 타서 학회장 가는 버스에 혼자 탑승.

Neural Strands: Learning Hair Geometry and Appearance from Multi-View Images. Neural Strands가 여기 나온 연구였음. 남겨둔 메모가 있으니 가져와보면:
multi view 이미지들에서 머리카락의 기하학적 구조를 추출해서 렌더링하는 프레임워크. 기하학적 구조를 추출하기 때문에 편집이 용이하다고 주장하고 있네요. 이전에 언리얼 엔진 데모 같은 것에서 머리카락 렌더링을 티저로 사용하곤 했었는데 그런 게 좀 생각나네요.

Improved Masked Image Generation with Token-Critic. 마침 요즘 관심 있는 주제에 대한 연구 포스터. 포스터를 붙이고 있길래 살짝 거들었음. 이런 masked image generation이 pixel level diffusion에 대해 가지는 장점이 무엇이라고 생각하냐고 물으니 빠른 샘플링 속도를 장점으로 제시. 퀄리티 측면에서 동등하다고 보지만 vq-vae 사용으로 인해 texture에 대한 재현이 약할 수 있지만 global structure에 대해서는 괜찮은 것 같다고 제안. (혹은 더 나을 수 있는 가능성도.)
critic 학습에 얼마나 걸렸는지 물으니 큰 모델이라 4~5일 정도 걸렸다고 함. GPU/TPU를 얼마나 쓴 조건인지는 제대로 못 들었지만.
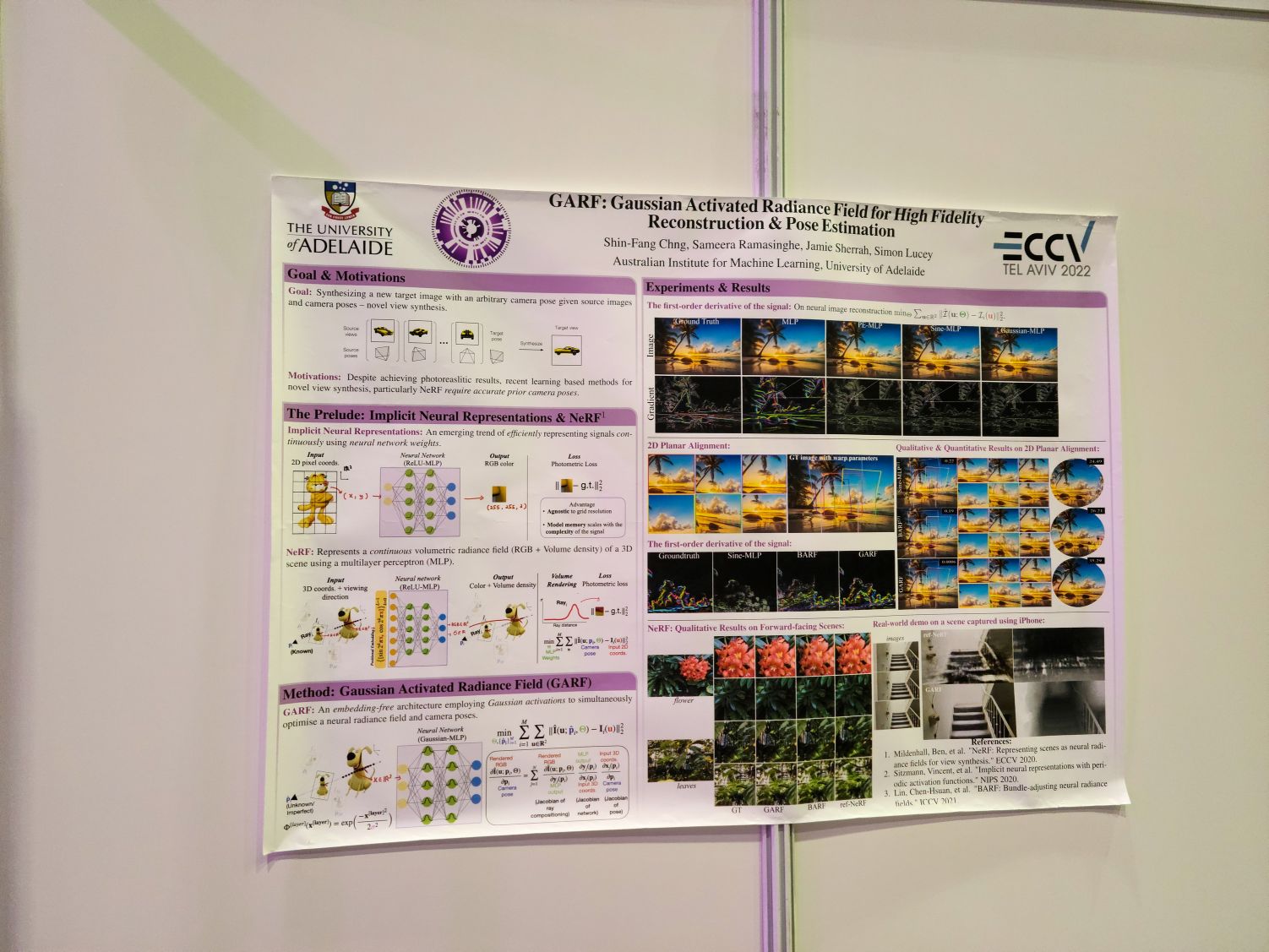
GARF: Gaussian Activated Radiance Fields for High Fidelity Reconstruction and Pose Estimation
nerf에서 pose estimation을 동시에 수행/학습하는 방법에 대한 연구. 직관이나 분석에 대해서도 설명해줬는데 아주 흥미로웠음. 좌표에 대한 그냥 relu mlp를 돌리면 low rank(혹은 low frequency) 매핑이라 성능이 불충분하고 (코멘트가 정확히 기억나지는 않는다.) positional encoding을 사용하면 이 문제는 해소되지만 그래디언트의 패턴이 썩 좋지 않음. sinusoidal (SIREN) activation을 사용하면 해소되지만 sinusoidal function은 거의 모든 지점에서 그래디언트가 0 이상이기 때문에 initialization에 민감하게 반응. GARF는 gaussian activation을 사용해서 이 문제들을 모두 해소. BARF의 경우에는 이런 문제들 때문에 커리큘럼 같은 것이 필요했는데 그런 것이 필요하지 않다고. positional encoding을 없애고 gaussian activation으로 바꾼 다음 학습하면 그냥 된다고 함.
굳이 colmap을 쓸 필요 없이 앞으로는 그냥 이걸 쓰면 된다고 하는 정도로 이야기함. 굉장히 흥미로워서 좀 더 분석한 다음 nerf 구현에 밀어넣어보고 싶음.
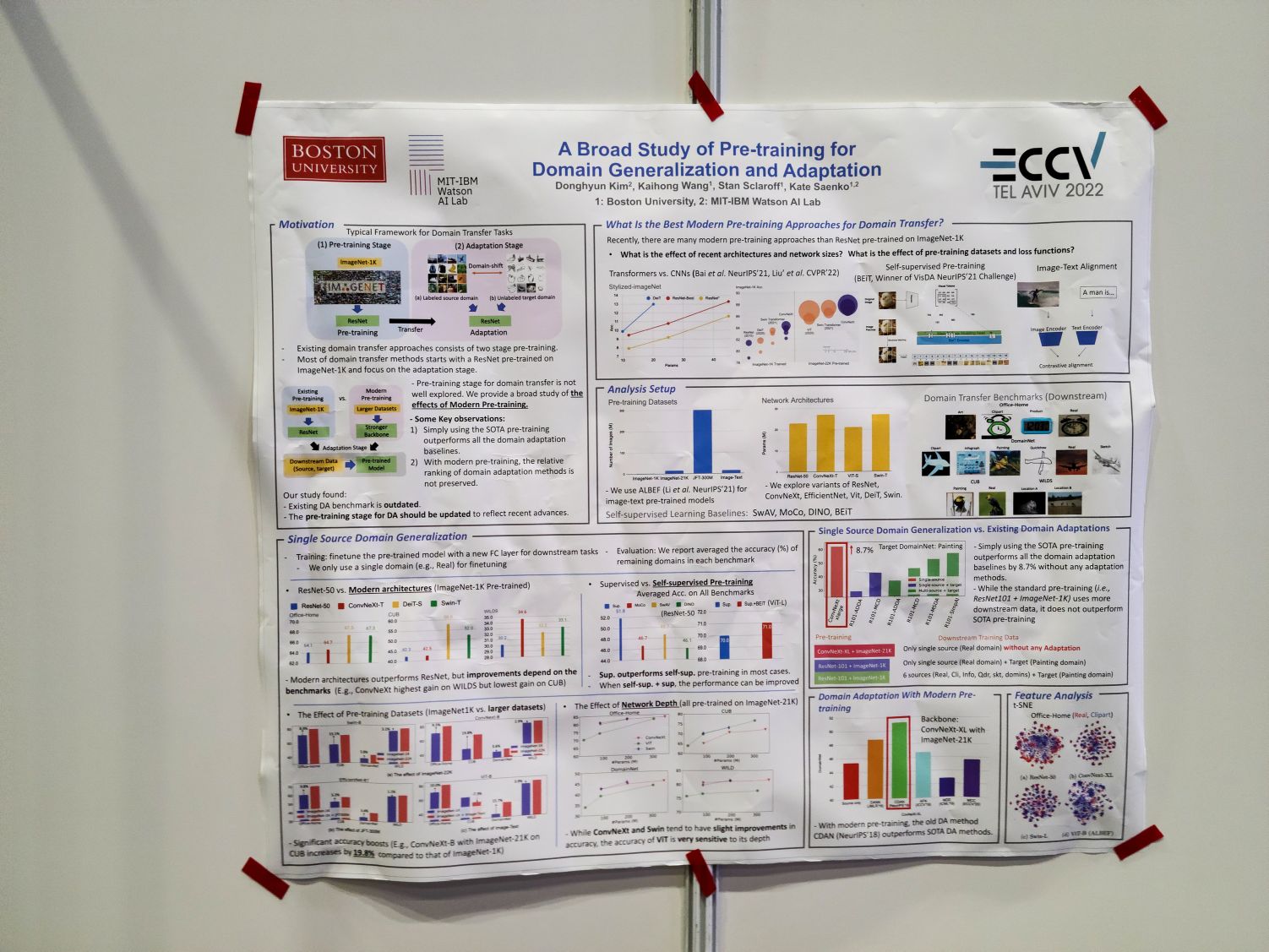
A Broad Study of Pre-training for Domain Generalization and Adaptation. 여러 프리트레이닝 방법, 데이터셋, 아키텍처의 domain generalization 성능에 대한 연구. domain generalization/adaptation 데이터셋들과 imagenet-a 같은 robustness 데이터셋에서 나타나는 패턴이 다른가 하는 질문을 하니 개념적으로 비슷한 부분들이 있지만 데이터셋의 규모 같은 차이로 인해 패턴이 일치하지 않는 경우가 있다는 이야기를 들었다.
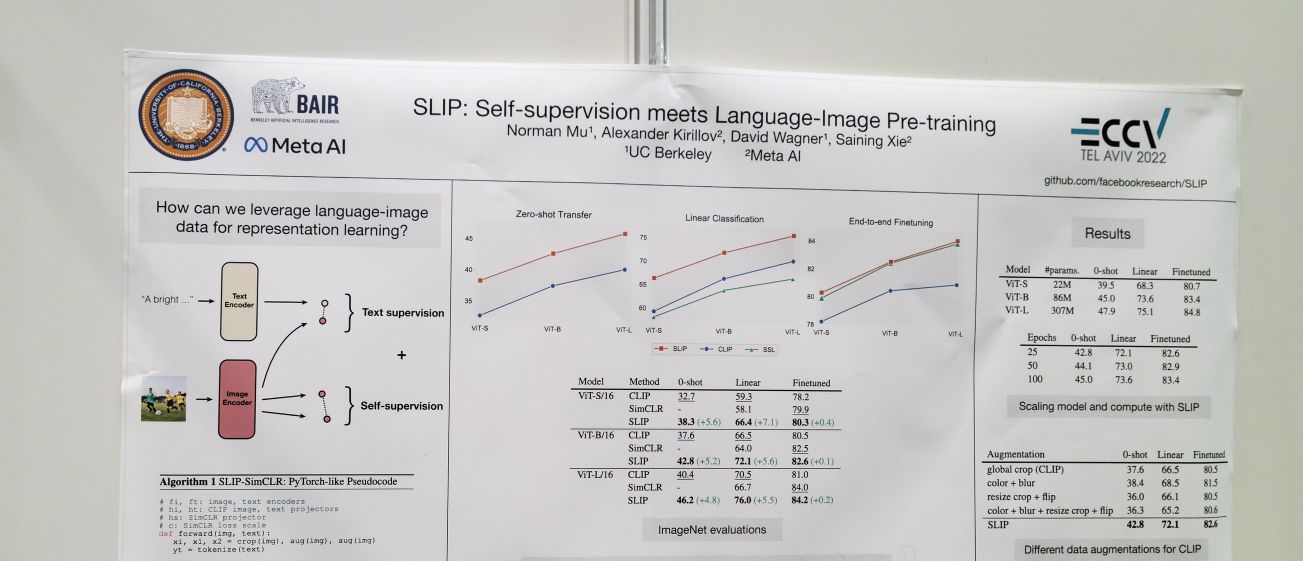
SLIP: Self-supervision meets Language-Image Pre-training. clip pretraining + self-supervised (contrastive) pretraining for image backbone. 성능 향상이 눈에 띄는 정도였음. 한 가지 흥미로웠던 부분은 beit 같은 masked image modeling보다 simclr 같은 contrastive training이 (이미지 self supervision에만 적용하는 경우에는 beit가 나음에도) clip pretraining과 결합했을 때 더 나았다는 것. 왜 그런지 물어보니 미스테리하지만 (이 부분은 잘 기억나지 않음) image self supervision이 추가적으로 보강해주는 부분에서 차이가 있는 것이 아닌가 하는 이야기. openai clip은 더 대규모의 이미지-텍스트 페어에 대해서 학습했는데 그 규모에서도 향상이 있을지 물어보니 그 규모까지 외삽하는 것은 어렵지만 논문 내에서 다룬 데이터셋들에서도 데이터셋이 커져도 성능 향상은 있었다는 것을 고려할 때 gain이 있을 수 있지 않을까 하고 제안.
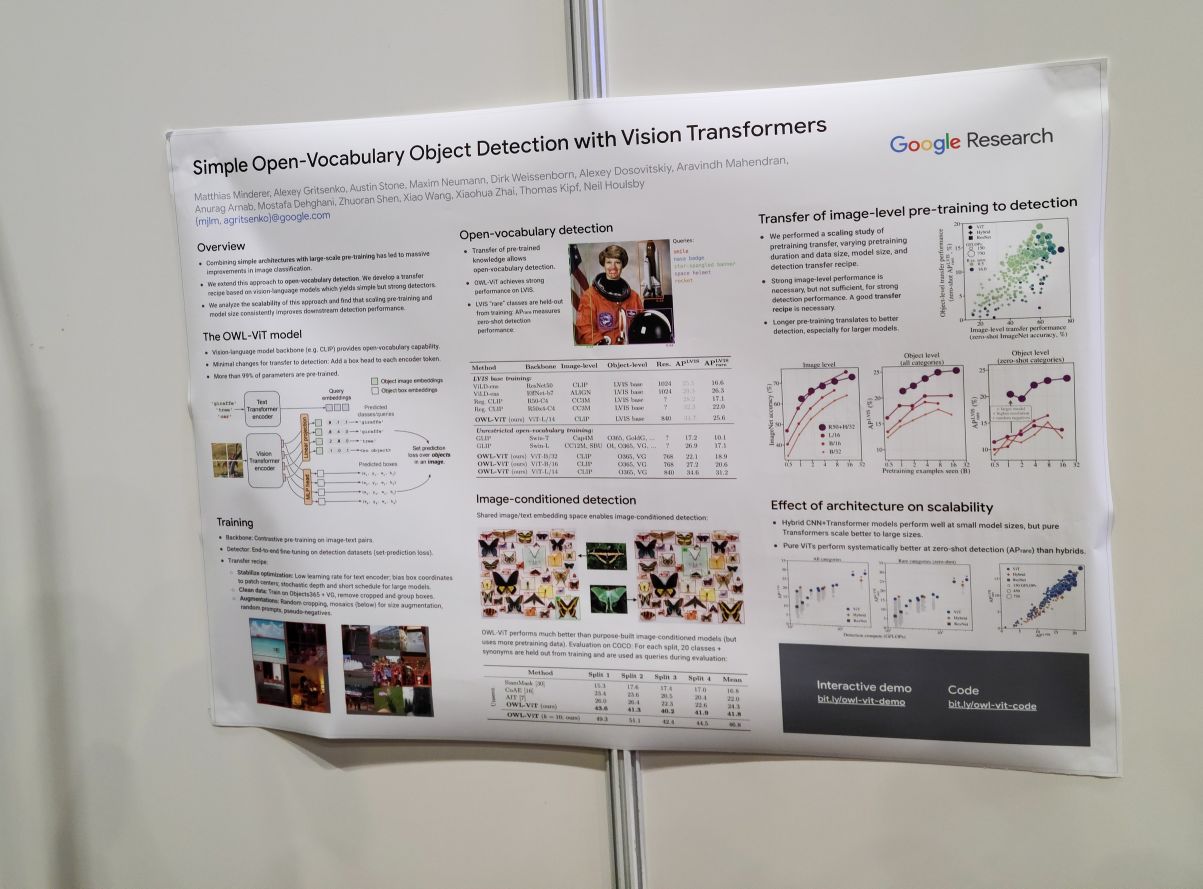
Simple Open-Vocabulary Object Detection with Vision Transformers. OWL-ViT. GLIP하고 비교하면 어떤지 물어보니 OWL-ViT는 심플함을 추구해서 GLIP에 있는 image-text feature fusion 같은 요소들을 제외했다고. 그러니 GLIP이 성능의 포텐셜은 더 높을 수도 있지 않겠느냐고 이야기함. 그런데 실험 테이블에서는 GLIP보다 OWL-ViT가 더 나은데? 라고 묻자 글쎄 그건 왜 그런지 우리도 잘 모르겠네 이런 이야기를 나눔. 😂

Detecting Twenty-thousand Classes using Image-level Supervision. 어쩌다 카메라가 제대로 흔들렸네.
이미지 단위 레이블 정보를 object detection에 활용하기. (weak supervision) 특별한 절차 없이 가장 큰 proposal 박스에 이미지 레이블을 부여해서 학습시키네요.
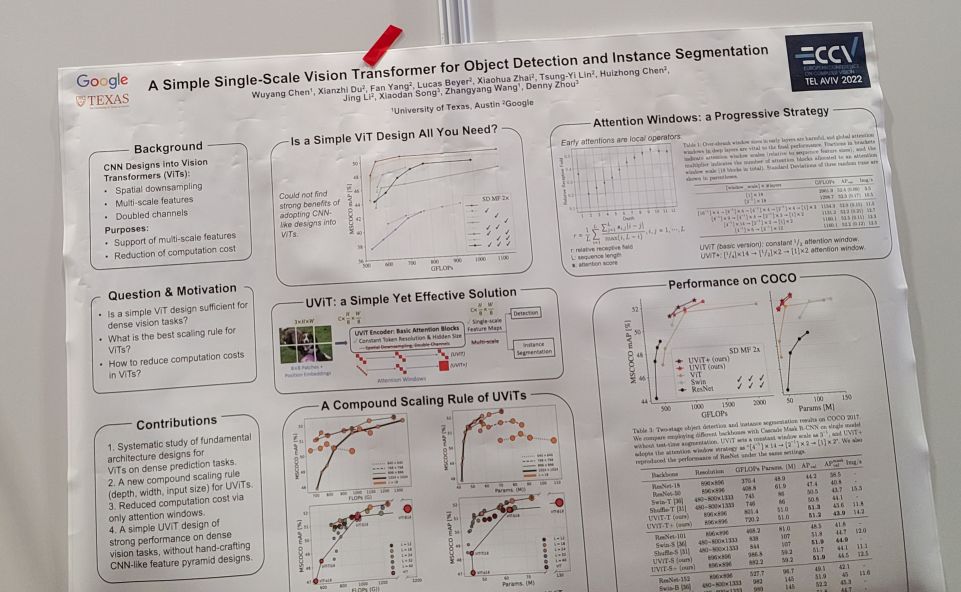
A Simple Single-Scale Vision Transformer for Object Localization and Instance Segmentation
vit에서 multiscale 구조는 딱히 필요하지 않고 single scale로 레이어를 쭉 쌓아도 좋다는 결과. 다만 연산이 비효율적이니 window attention을 활용하는데 이 window 크기를 점진적으로 키우는 구조는 고려해봤네요. 다 좋은데 이 window attention이 overlapping window 기반이라…이걸 구현하는 게 문제긴 하네요. single scale swin 같은 구조가 가능할까 싶기도 한데요.
detection head는 cascade mask r-cnn 기반. (벤치마크를 깨겠다는 의지가 충만해보이는 선택이라고 할 수 있음.) detection head도 심플하게 만드는 방향을 충분히 생각해볼 수 있겠다.

ViewFormer: NeRF-free Neural Rendering from Few Images Using Transformers
nerf rendering 파이프라인 없이 트랜스포머에 position 정보를 입력한 다음 이미지를 바로 생성. 이미지는 잘 나오지면 역시 3d consistency를 보장하기 어렵다는 것이 주된 문제일 듯.


그 와중에 학회 점심은 또 챙겨먹음.

오후 시간에 디젠고프 센터(Dizengoff Center)에 들렀음. 텔 아비브 최대 쇼핑몰이라는 듯. 복잡하고 이것저것 많았는데 흥미로운 것이 서브컬쳐나 오타쿠스러운 상품을 취급하는 가게들이 꽤 많았음. 사진은 없지만 진격의 거인이나 귀멸의 칼날 같은 서구권에서 인기 있기로 유명한(?) 것도 그렇지만 특히 눈에 띈 것이 원신. 원신 굿즈가 정말 많았음. 이스라엘에서 원신을 한다는 게 잘 상상이 안 되는데…여튼.

그 다음은 텔 아비브의 구 시가지 올드 야파로.

올드 야파의 시계탑. 여기 있는 시장은 카멜 마켓보다 더 좁고 구불구불했다.

일행 중 한 분이 극구 추천해서 맛본 크나페(쿠나파? Knafeh)와 터키식 차. 아이스크림을 얹은 바리에이션인데 정말 맛있었음.


거리를 지나 올라가는 길.

중간에 만난 모스크.



올라가는 길에 베드로 환시 기념 성당을 만나 내부에 들어가볼 수 있었다. 마침 미사가 끝난 바로 직후 타이밍이라(17시) 수사로 보이는 분이 관대하게 들여보내주셨음. 환시 기념이라는 아우라 때문인지 느껴지는 감흥이 있었다. 예루살렘에 가본 분도 있었는데 여기 와보고 나서 그 분들이 좀 부럽다 하는 생각을 처음 했음.
환시 기념 성당이라는 것이 대체 무슨 의미냐는 이야기가 나왔는데 일행 중 한 분이 코셔 안 지켜도 된다고 한 사건이라고 단 번에 요약해내셔서 좀 재미있었음.

올드 야파의 골목길. 이렇게 성벽처럼 높은 벽들 사이로 길이 나 있고 그 벽에 집들이 들어가 있는 구조였음.


골목길을 지나가다 만난 무두장이 시몬의 집.


내려가는 길에서 만난 바다.



텔 아비브에서의 마지막 저녁. 루마니아 레스토랑이라는 곳에 들어감. 커틀릿.

또드스타 맥주.
이 날은 이것으로 마무리.

