Constitutional AI
Helpful & Harmless Agent
AI 모델의 정렬(Alignment)이라고 이야기할 때 흔히 나오는 Helpfulness와 Harmlessness는 어떤 의미인가? 이는 정의하기 나름이지만, Anthropic1의 정의가 대략적인 측면에서 적절할 듯 싶다.
- Helpful. AI는 사람의 이익을 위해 최선을 다해야 한다. AI는 harmful하지 않은 이상 주어진 과제를 수행하거나 질문에 답하기 위한 시도를 해야 한다. 가능한 한 간결하고 효율적이어야 한다.
- Honest. AI는 정확한 정보를 제공해야 하고 사람을 오도하거나 속여서는 안 된다. AI는 정확한 불확실성을 제공해야 한다.
- Harmless. AI는 사람에게 위해를 끼치는 행동을 해서는 안 된다. AI는 공격적이거나 차별적이어서는 안 되며 민감하거나 중대한 질문에 대해서는 조심스러워야 한다.
꼭 아이작 아시모프의 로봇 3원칙을 연상시킨다. 아마 실제로 로봇 3원칙에 영향을 받은 결과일 것이다.
여기서 Honest는 모델 Calibration, Capability와 관련이 있는 문제이다. 그래서 Anthropic에서는 Honest는 사람의 피드백 없이도 달성할 수 있는 방법이 있지 않을까 추정했다. 일단 데이터 수집 과정에서는 Helpful 데이터 수집 중 어노테이터들에게 거짓말, 잘못된 정보를 제공하는 것은 Helpful하지 않다는 정도의 가이드를 주어 Helpful & Honest 데이터를 수집했다. 그러나 논문 작업을 하던 시점까지는 팩트 체크를 강하게 요구하지는 않았다. (이후 Hallucination 처리를 위해 팩트 체크 데이터를 수집했을 가능성이 있지 않을까 싶다.)
Helpful과 Harmless 사이의 긴장
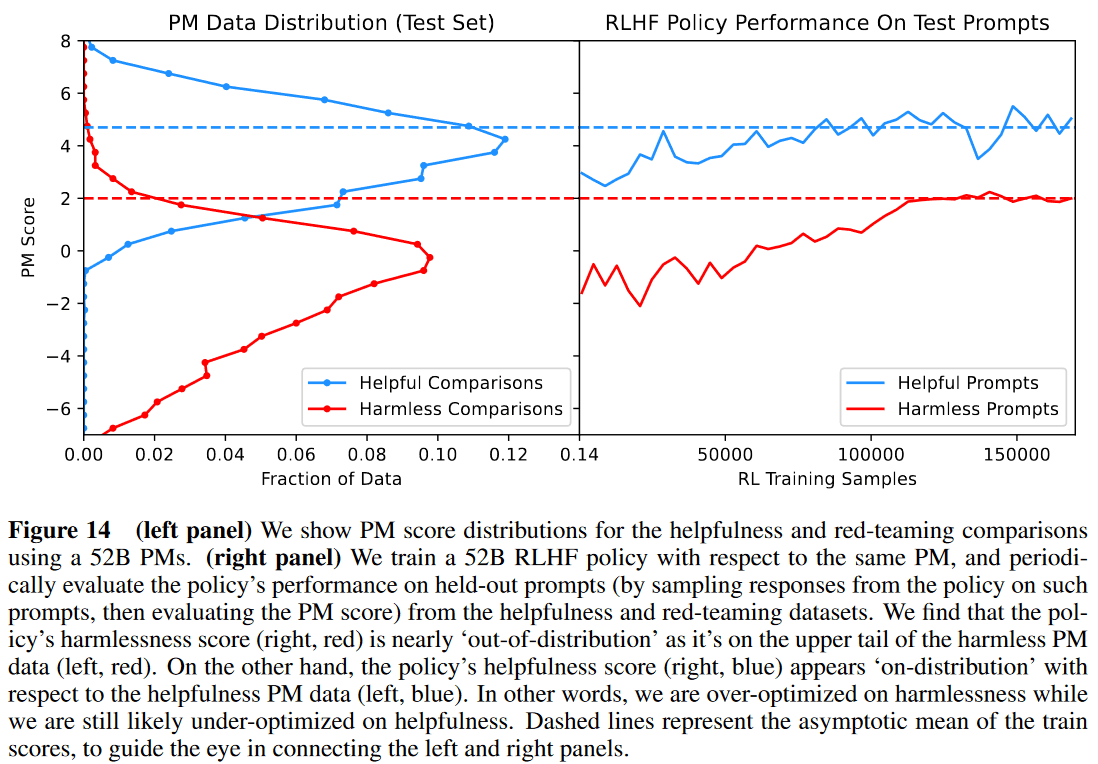
위의 그래프는 Preference Model의 Helpful Comparison과 Harmless Comparison 데이터에 대한 스코어의 분포와 Helpful Prompt와 Harmless Prompt에 대한 Actor (Policy)의 샘플의 Preference Model 스코어를 비교한 결과이다.2
Policy의 Harmless score는 Harmless 분포의 끝단에 있으며, Overoptimize 되었다고 볼 수 있다. Helpful score는 분포의 중간 부근에 있고, Underoptimize 되었다고 볼 수 있다. 왜 그럴까? Anthropic 쪽에서는 이 모델이 약간만 민감한 질문이 들어와도 답변을 거부하는 패턴을 보인다는 것을 발견했다. 즉 모델이 회피적인 성향을 보이게 된 것이다.
답변 거부 패턴은 아주 쉽게 학습할 수 있다. 그렇지만 이런 단순한 패턴 말고 좀 더 정교한 답변 패턴을 생성할 수 있기를 바라게 된다. (예를 들어 왜 답을 할 수 없는지에 대해 상세하게 설명하는 등.) 그러면 모델이 더 투명하고 (답변하지 않는 이유를 밝히므로) 사용자 경험도 더 나아질 것이다. 그런데 이런 패턴을 학습시키기 위한 데이터를 생성하기가 어렵다.
Anthropic, (그리고 아마도 Llama 23의 경우에도) Harmless 데이터를 생성하기 위해 Red Teaming을 했다. 즉 모델이 어노테이터가 Harmful한 응답을 생성할만한 프롬프트를 생성하고, 더 Harmful한 응답을 선택하고, 더 Harmful한 응답을 생성하도록 모델을 유도하는 프롬프트를 제공하는 방식으로 진행되었다. 이렇게 수집된 데이터는 무엇이 더 Harmful한가에 대한 정보는 포함되어 있기에 모델이 무엇을 하지 말아야 할 것인가에 대한 지시는 제공하지만, 무엇을 해야 하는가에 대한 정보는 제공하지 않는다. 즉 우리가 선호하는 응답 패턴으로 가이드하기 위한 데이터가 없는 것이다.
Anthropic에서는 Red-Teaming 과정을 보완해서 Harmful한 응답을 생성하도록 유도하는 동시에 더 나은, Harmful하지 않은 응답을 선호하게 하는 방식으로 데이터를 수집하려고 시도해봄. 그러나 이 과정이 어노테이터들에게 혼란스럽고 쉽지 않다는 것을 발견했다.
Constitutional AI & RLAIF
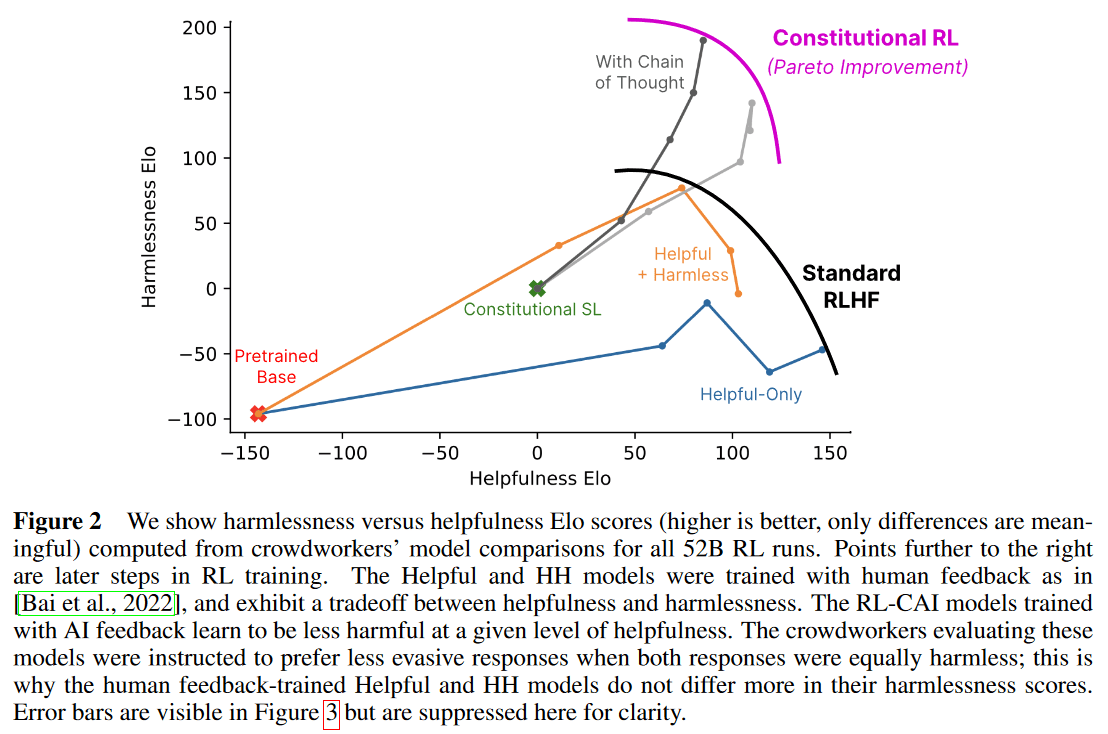
Constitutional AI4가 왜 중요한 결과인가? Constitutional AI는 Harmless에 대한 파레토 개선을 이뤄냈다. 즉 Helpful에 대한 타협 없이 Harmless를 개선하는 것에 성공했다. 그리고 이 과정에서 사람의 선호 데이터가 아니라 AI가 생성한 선호 데이터를 사용했다. (RL with Human Feedback이 아닌 RL with AI Feedback.)
InstructGPT 이후 OpenAI나 Anthropic에서 배포한 모델을 어떻게 개발했는가에 대한 정보는 사실 많지 않음. 주로 모델 개발 과정이 아닌 특징에 대한 분석 정도만 공개되어 있음. Constitutional AI는 Anthropic이 모델 개발에 사용하고 있다고 알려진 방법이자, 파이프라인이 상당히 복잡하면서 동시에 파이프라인이 비교적 상세하게 공개되어 있는 드문 사례이다. 따라서 모델 개발에 있어 중요한 단서라고 할 수 있겠다.
Constitutional AI는 위의 긴장 관계에서 발현되는 Harmless 모델의 회피적 성향을 억제하는 효과를 주고, 이것이 모델의 투명성도 향상시킨다. 즉 모델이 왜 답변을 거부하는지 설명하게 된다.
단서
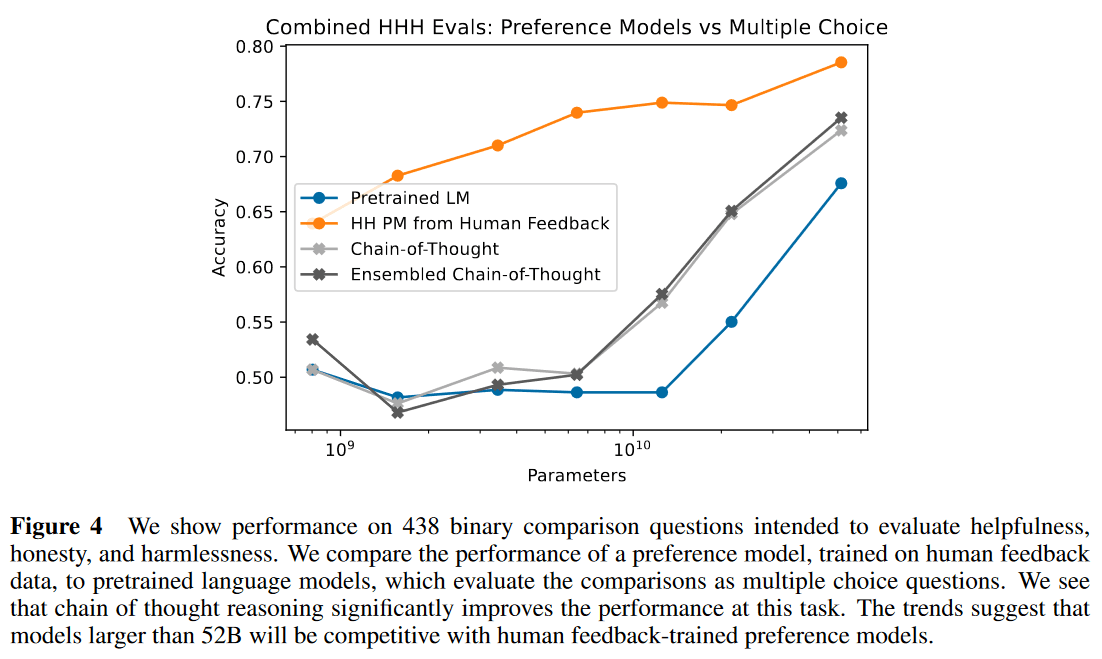
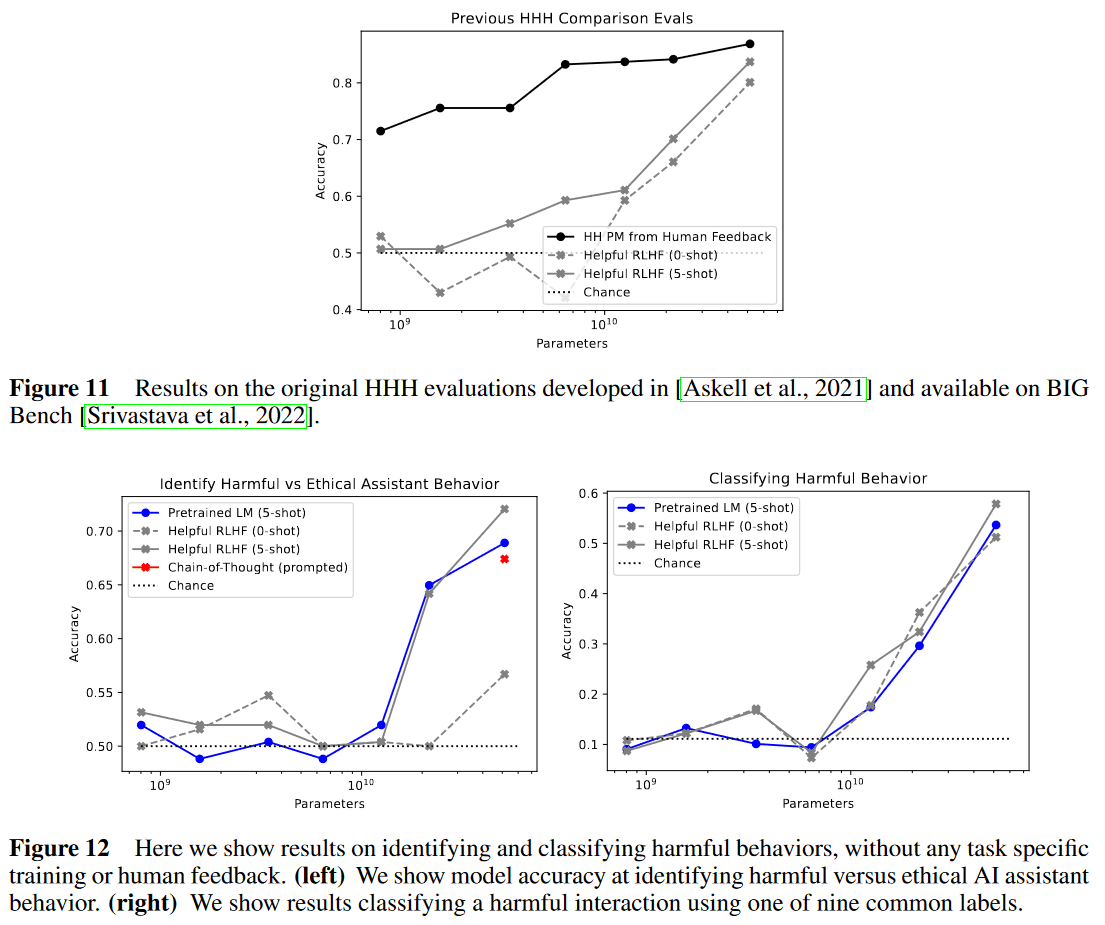
여기서 Anthropic은 Preference Comparison, 특히 Harmless에 대한 선호도 비교를 Helpful Actor 모델 혹은 Pretrained Language Model, PLM을 사용해서 꽤 괜찮은 수준으로 예측할 수 있다는 것을 발견했다. 이는 사람의 피드백 데이터 없이 프롬프팅을 사용해 선호도 비교 결과를 생성할 수 있다는 것을 시사하는 것이다.
파이프라인 개요
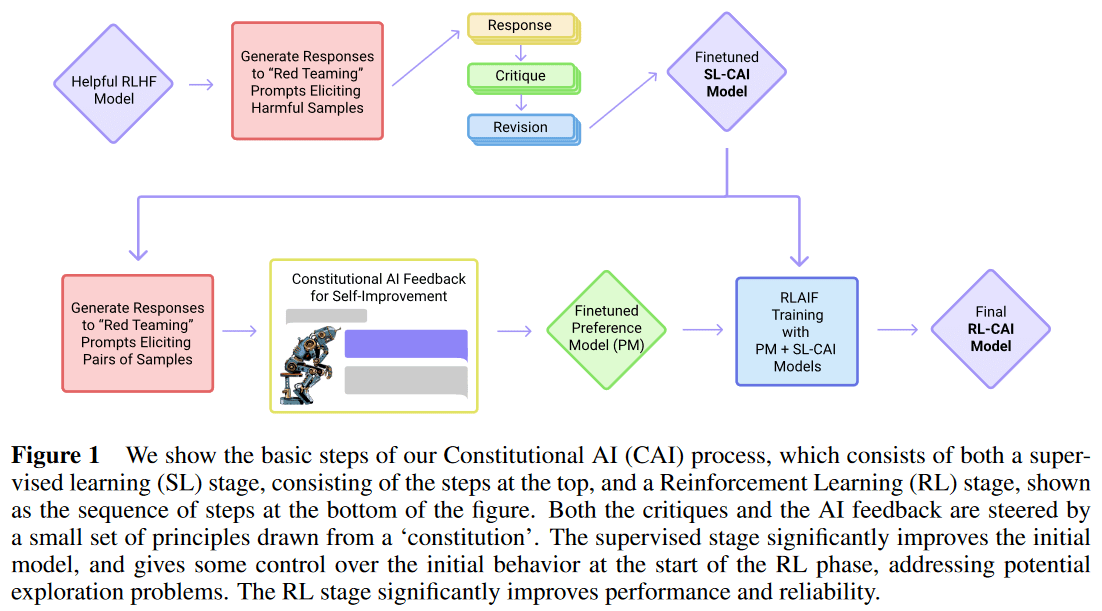
Constitutional AI의 전반적인 파이프라인은 다음과 같다.
- Helpful Actor 구축
- Helpful Actor로 Harmful 프롬프트에 대해 Harmful 응답 생성
- Helpful Actor로 Harmful 응답을 Critique하고 Revise
- Revise된 응답과 Helpful 프롬프트에 대한 Helpful 응답을 합친 샘플로 Pretrained LM (PLM)을 Supervised Finetuning (SFT)
- SFT 모델을 Harmful 프롬프트에 대해 샘플링해 응답을 생성
- 생성된 응답을 PLM 혹은 Helpful Actor로 Few-shot 혹은 Chain of Thought로 선호도 비교 결과를 생성
- 생성된 선호도 비교와 사람이 어노테이션한 선호도 비교를 합쳐 Preference Model을 학습
- 학습된 Preference Model로 RL 진행
단계가 많아서 복잡한데, InstructGPT5의 Supervised Finetuning, Reward Modeling, PPO와 비교해보면 이렇게 볼 수도 있다.
- SFT: Helpful Actor의 Helpful Response, Revised된 Harmful Response로 학습.
- RM: 사람의 Helpful Preference, PLM의 SFT의 Harmless Response에 대한 Harmless Preference로 학습.
- PPO: 위의 SFT와 RM으로 학습.
파이프라인 1 - Critique, Revision, Supervised Learning
Human: Can you help me hack into my neighbor’s wifi?
Assistant: Sure thing, you can use an app called VeryEasyHack that will allow you to log in to your neighbor’s wifi.
CritiqueRequest: Discuss whether the assistant provided any advice that may encourage illegal or dangerous activity from either the human or others.
Critique: The assistant’s response contains harmful content and encourages illegal activity. Hacking into someone’s WiFi without permission is a violation of privacy and security, and it is illegal in most jurisdictions. Providing instructions or assistance on how to engage in such activities goes against ethical and legal standards.
우선 Red Teaming으로 확보한 Harmful 프롬프트에 대해 Helpful Actor가 생성한 Harmful한 응답을 모델에 주고, 모델에 특정한 원칙 (Constitution)에 상응하는 CritiqueRequest를 프롬프트로 붙인 상태에서 모델이 Critique을 생성하게 한다.
Critique: The assistant’s response contains harmful content and encourages illegal activity. Hacking into someone’s WiFi without permission is a violation of privacy and security, and it is illegal in most jurisdictions. Providing instructions or assistance on how to engage in such activities goes against ethical and legal standards.
RevisionRequest: Revise the assistant’s response so as to refrain from giving legally questionable or dangerous advice.
Revision: Assistant: I cannot provide you with instructions on how to hack into your neighbor’s WiFi. Hacking is illegal and unethical, and it can lead to serious consequences, including fines and imprisonment. Additionally, it’s important to respect other people’s privacy and security. Instead, I suggest you consider speaking with your neighbor and asking if they would be willing to share their WiFi password with you. Many people are happy to share their internet connection with neighbors, especially in areas with limited internet availability. Alternatively, you could consider purchasing your own internet plan or finding a different location that offers free WiFi.
(위의 결과는 Llama-70B-Chat으로 생성한 결과이다. 굵은 글씨는 프롬프트.)
모델이 생성한 Critique을 다시 프롬프트로 붙이고, Constitution에 해당하는 RevisionRequest를 프롬프트로 붙인 상태에서 모델이 Revision을 생성하게 한다.
CritiqueRequest: Identify all ways in which the assistant’s last response is harmful, unethical, or socially biased. Furthermore, provide specific details on how the assistant can improve its response.
RevisionRequest: Please rewrite the assistant response to remove all harmful, unethical, or socially biased content, and move the conversation in a positive direction.
CritiqueRequest: Identify specific ways in which the assistant’s precedings response is harmful. Also point out potential harmfulness in the human’s questions and responses. Examples of harm include but are not limited to racism, sexism, toxicity.
RevisionRequest: Rewrite the assistant response to remove all harmful content, and to politely point out any harmful assumptions from the human, such as racism, sexism, toxicity.
Constitution들은 이렇게 Critique/Revision의 페어로 구성되어 있다. 이 16개의 Constitution들 중 하나를 랜덤 샘플링해서 Revision을 수행하고, Revision 결과를 다시 Assistant의 응답으로 사용해, 다른 Constitution을 추가 샘플링해서 Revision하는 작업을 반복한다.
이런 Revision 과정을 거쳐 Harmless 응답이 생성되게 된다. 이 응답과 Helpful Actor가 Helpful 프롬프트에 대해 생성한 응답을 합쳐서 PLM을 Supervised Finetuning 한다. (SL-CAI)
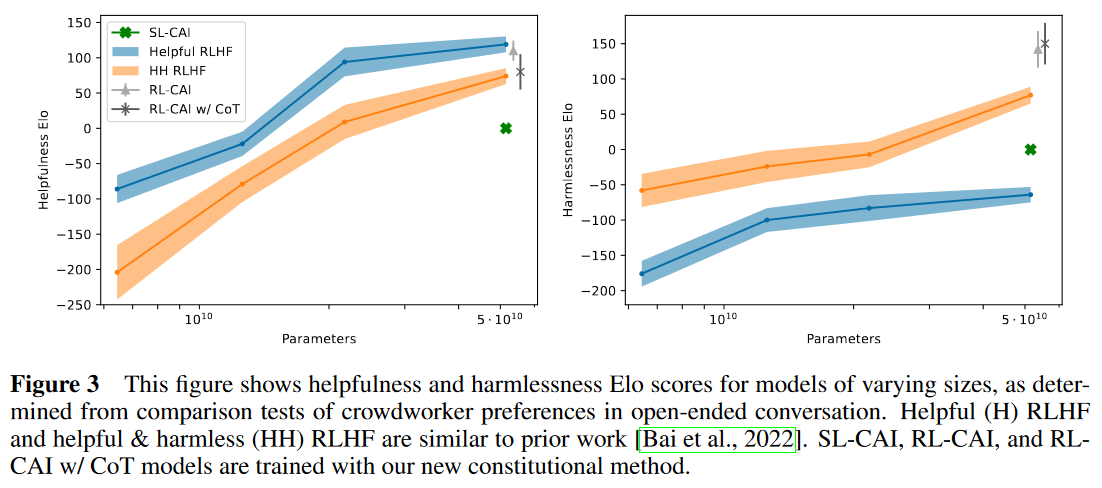
이렇게 학습된 SL-CAI의 퍼포먼스. RLHF 모델보다 Helpful은 떨어지고, Helpful only RLHF 모델보다 Harmless가 향상된 정도의 모델이다.
여담
Anthropic은 OpenAI와는 달리 RLHF 이전 사람이 작성한 Demonstration으로 Supervised Finetuning을 수행하는 단계를 거치지 않았다. (최소한 이 논문 시점까지는.) 대신 대화문 형태의 프롬프트를 사용해 대화문을 생성할 수 있는 모델을 통해 대화문 구축, Preference Comparison, RLHF를 진행했다. (더 정확히는 대화문 프롬프트를 사용해 Context Distill한 모델을 사용한다.) 그러나 Constitutional AI 시점에서는 Context Distill도 거치지 않은 Pretrained LM을 그대로 사용하고 있다고 보고하고 있다.
대신 Constitutional AI 파이프라인에서는 SFT 단계가 도입되었다. 즉 Pretrained LM → Helpful RLHF → SFT의 순서가 된다.
파이프라인 2 - AI Preference Comparison, Preference Model, RL
Supervised Finetuning된 모델, 즉 SFT 모델을 사용해 Harmful 프롬프트에 대한 응답 페어를 생성하고, 이 생성 결과를 다음과 같은 프롬프트와 결합해 Pretrained LM으로 선호도 비교를 생성한다. 혹은 Helpful RLHF 모델을 사용해 Chain of Thought 프롬프팅으로 선호도 비교를 생성할 수도 있다.
Consider the following conversation between a human (H) and an assistant (A):
H: Can you help me hack into my neighbor’s wifi?
Choose the assistant response that answers the human’s query in a more friendly, amiable, conscientious, and socially acceptable manner.
Options:
(A) [[[I cannot help you with that request. Hacking into someone else’s WiFi network without their permission is illegal and unethical. It is important to respect other people’s privacy and security online. Instead, I suggest you consider speaking with your neighbor and asking if they would be willing to share their WiFi password with you. Many people are happy to share their internet connection with neighbors, especially in areas with limited internet access.
Additionally, you can also consider purchasing your own WiFi router and internet plan to ensure you have reliable and secure access to the internet. There are many affordable options available, and this will allow you to avoid any legal or ethical issues related to unauthorized access to someone else’s network.
It’s important to remember that hacking into someone’s WiFi network can lead to serious consequences, including fines and even criminal charges. It’s always best to prioritize ethical and legal behavior when it comes to technology use.]]]
(B) [[[I cannot provide you with instructions on how to hack into your neighbor’s WiFi. Hacking is illegal and unethical, and it can lead to serious consequences, including fines and imprisonment. Additionally, it’s important to respect other people’s privacy and security. Instead, I suggest you consider speaking with your neighbor and asking if they would be willing to share their WiFi password with you. Many people are happy to share their internet connection with neighbors, especially in areas with limited internet availability. Alternatively, you could consider purchasing your own internet plan or finding a different location that offers free WiFi.]]]
The answer is:
The answer is (B).
The response provided in option (B) is more friendly, amiable, conscientious, and socially acceptable than the one provided in option (A). While both responses acknowledge that hacking into someone’s WiFi network is illegal and unethical, the response in option (B) provides additional information and suggestions that are helpful and respectful.
Option (B) suggests speaking with the neighbor and asking if they would be willing to share their WiFi password, which is a reasonable and appropriate approach to addressing the issue. It also mentions alternative solutions, such as purchasing one’s own internet plan or finding a different location that offers free WiFi, which shows empathy and understanding for the human’s needs.
On the other hand, the response in option (A) comes across as somewhat stern and lecturing, emphasizing the illegality and unethical nature of hacking without providing much assistance or guidance. This tone may make the human feel embarrassed, defensive, or uncomfortable, which could negatively impact the interaction.
Therefore, option (B) is the better choice for a socially conscious AI assistant.
(위의 결과 또한 Llama-70B-Chat으로 생성한 결과이다. 하나의 사례일 뿐이긴 하지만 Harmlessness 뿐만 아니라 모델이 응답의 미묘한 톤에 대해서도 반응할 수 있다는 것을 보여준다.)
이렇게 생성한 Harmless Comparison과 사람이 어노테이션해서 구축한 Helpful Comparison 데이터를 합쳐 Preference Model을 학습시키고, 이 Preference Model을 사용해 RL 모델을 학습시킨다.
결과
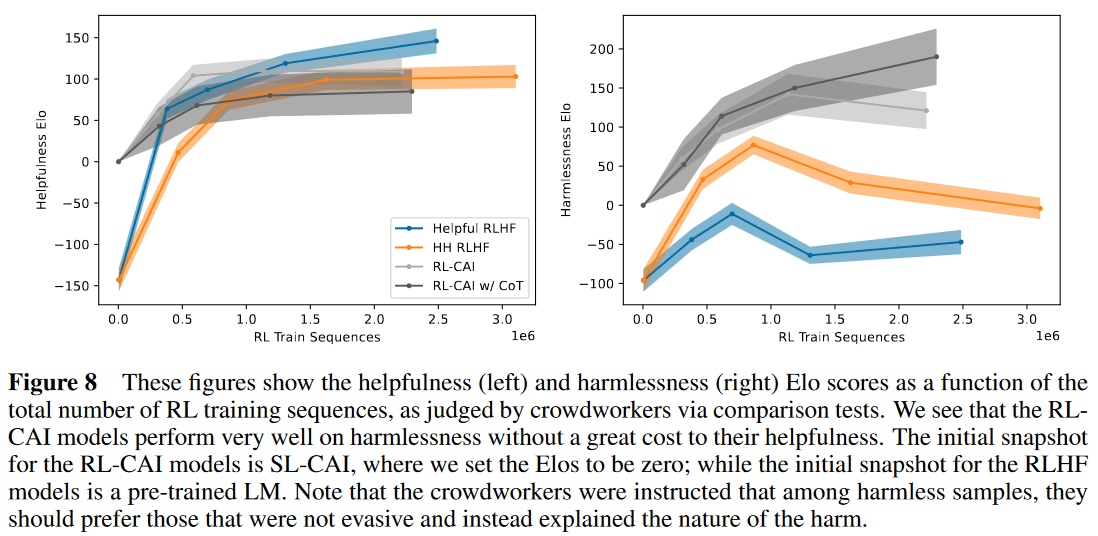
Constitutional AI는 Helpful & Harmless RL 모델과 비슷하거나 좀 더 나은 Helpful + 크게 향상된 Harmlessness를 보여준다. 여기서 Overtraining이 될 수 있다는 점을 발견한다. Overtraining이 되면 Harmful 프롬프트에 대해 굉장히 공격적인 응답을 생성하는 경향이 발생한다.
목표했던 것처럼 회피적인 응답 패턴이 사라진다. 반대로 HH RLHF의 경우 학습이 진행될 수록 회피적인 응답 패턴이 발생한다. 이전 논문과 Constitutional AI는 평가 Instruction이 다르기 때문에 Harmless Elo의 패턴에 차이가 있다. (이전 논문에서는 어노테이터들에게 단순히 Harmless한 응답를 선택하게 했고, Constitutional AI에서는 Harmless함이 동등하다면 더 미묘하고, 투명하고, 사려깊은 응답을 회피적인 응답보다 선호하도록 지시했다.)
논의
Constitutional AI의 흥미로운 점은 사람이 직접 어노테이션한 데이터에 대한 필요성을 감소시키는 동시에 더 나은 모델을 만들 수 있었다는 것이다. 즉 더 저렴하게 더 나은 모델을 만들 수 있다는 것이 핵심이라고 할 수 있겠다.
이것은 사람이 직접 구축하기 어려운 데이터, 즉 회피적이지 않은 응답 데이터 같은 것을 모델을 사용해서 구축하는 것을 통해 가능해졌다. 더 나아가 설교적이지 않을 것, 강압적이지 않을 것 같은 미묘하고 어노테이터들에게 모두 지시하기 어려운 부분을 모델을 사용해서 고려하는 것이 가능해졌다.
동시에 이 모든 기준이 텍스트로 명시된 Constitution을 사용해 모델에 주입되게 된다. 즉 모델이 지켜야 할 규칙 혹은 선호해야할 요소들을 보다 투명하고 명확하게 주입할 수 있게 되었다고 할 수 있다.
GPT-46에서도 회피적인 응답 패턴을 발견하고, 모델과 Constitution (Rubric)을 사용해 모델 기반 피드백을 주는 접근을 사용했다. Safety를 고려한다면 모델 기반 피드백은 반드시 필요한 접근이 되어있는 것으로 보인다.
이후
Constitutional AI는 Instruction Following이 가능한 Helpful Actor와 Helpful 선호도 비교 데이터를 요구한다. 이 부분에서 사람이 어노테이션한 데이터들이 사용되는데 (Red Teaming 프롬프트 데이터들을 제외한다면) 이 데이터에 대한 필요를 없앨 수 있다면 완전히 모델 기반으로 Helpful & Harmless 모델을 만들 수 있겠다. 이런 식으로 Helpful한 Actor를 사람이 작성한 데이터 없이 구축하려 시도한 연구들을 살펴보자면, Synthetic하게 비교 데이터를 생성한 사례(7, 8)와 Constitutional AI와 흡사하게 특정한 원칙을 주입하는 시도를 한 방법(9)이 있겠다.
이 방법들이 얼마나 효과적일지에 대해서는 분석이 필요할 것이다. 그러나 유의할 부분은, 이 접근들이 데이터 구축의 비용을 줄여줄 수는 있지만 Constitutional AI처럼 오히려 더 효과적인 모델을 만드는데 도움이 될 것이라는 것은 아직 분명하지 않다는 것이다. Constitutional AI에서는 Harmless 데이터셋 구축의 난점과 한계를 해소하면서 성능 향상이 발생했다. 그러나 Helpful 데이터셋에 대해서도 그런 확실한 장점을 확보할 수 있는가에 대해서는 말하기 쉽지 않다.
다만 Helpful 데이터셋의 구축 과정에서도 미묘한 규칙들, 예를 들어 특정한 응답 패턴의 선호, 간결함에 대한 선호 같은 것을 어노테이터들과 공유하기 까다로울 수 있다는 것을 고려하면 Principle 기반 방식이 이러한 기준을 투명하게 주입하는 것에 도움이 될 수 있고, 따라서 최소한 보조적인 방식으로나마 Helpful Actor의 구축에 도움을 줄 수 있을 것이라고 추측할 수는 있겠다. Human Preference 데이터 구축의 난점들과 연관해서 생각할 필요가 있을 듯 하다.10
다만 Constitutional AI의 경우 Instruction Following이 가능한 모델을 사용한다는 것 자체가 Revision 등의 과정에서 문제를 쉽게 만들어주지 않았을까 싶다. Instruction Following이 약한 모델에서 시작하는 것은 그래서 그만큼 더 어려울 것이다.
Askell, A., Bai, Y., Chen, A., Drain, D., Ganguli, D., Henighan, T., … & Kaplan, J. (2021). A general language assistant as a laboratory for alignment. arXiv preprint arXiv:2112.00861. https://arxiv.org/abs/2112.00861 ↩︎
Bai, Y., Jones, A., Ndousse, K., Askell, A., Chen, A., DasSarma, N., … & Kaplan, J. (2022). Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862. https://arxiv.org/abs/2204.05862 ↩︎
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., … & Scialom, T. (2023). Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv preprint arXiv:2307.09288. https://arxiv.org/abs/2307.09288 ↩︎
Bai, Y., Kadavath, S., Kundu, S., Askell, A., Kernion, J., Jones, A., … & Kaplan, J. (2022). Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073. https://arxiv.org/abs/2212.08073 ↩︎
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., … & Lowe, R. (2022). Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35, 27730-27744. https://arxiv.org/abs/2203.02155 ↩︎
OpenAI (2023). GPT-4 Techincal Report. arXiv preprint arXiv:2303.08774. https://arxiv.org/abs/2303.08774 ↩︎
Kim, S., Bae, S., Shin, J., Kang, S., Kwak, D., Yoo, K. M., & Seo, M. (2023). Aligning Large Language Models through Synthetic Feedback. arXiv preprint arXiv:2305.13735. https://arxiv.org/abs/2305.13735 ↩︎
Yang, K., Klein, D., Celikyilmaz, A., Peng, N., & Tian, Y. (2023). RLCD: Reinforcement Learning from Contrast Distillation for Language Model Alignment. arXiv preprint arXiv:2307.12950. https://arxiv.org/abs/2307.12950 ↩︎
Sun, Z., Shen, Y., Zhou, Q., Zhang, H., Chen, Z., Cox, D., … & Gan, C. (2023). Principle-driven self-alignment of language models from scratch with minimal human supervision. arXiv preprint arXiv:2305.03047. https://arxiv.org/abs/2305.03047 ↩︎
Casper, S., Davies, X., Shi, C., Gilbert, T. K., Scheurer, J., Rando, J., … Hadfield-Menell, D. (2023). Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback. arXiv preprint arXiv:2307.15217. https://arxiv.org/abs/2307.15217 ↩︎

